 前端加油站🧠
前端加油站🧠Appearance
《JavaScript 忍者秘籍》记录
前言
这个记录顺序是按章节但是知识点是零散的记录,录入的内容并不会非常的细微,均是以我还不了解、不掌握、或觉得有意思/意义的知识点。
第一部分热身
这一章介绍了 JavaScript 的语言特性,以及核心要素,强调了 JS 的强大,能够实现一种语言开发各个方向的应用。一些概念性的问题终于明白了。
函数是一等公民
在 JS 中,函数与其他对象共存,并且能够像对象一样进行使用,可以通过字面量创建,可以赋值给对象,可以做为函数参数进行传参,甚至函数的返回值也可以是函数。
函数几乎无所不能,所以函数是 JS 的一等公民
web 应用的生命周期相关知识
典型的客户端 web 应用生命周期是在浏览器输入 url 之后链接开始,直到用户关闭了这个浏览器。
关键步骤,也是生命周期阶段:
- 页面构建
- 事件处理
为什么更加推荐使用
addEventLinstener而不是属性绑定事件如onclick使用
onclick只能绑定一个事件处理函数(事件监听器),写多个的效果只能是将之前的监听器进行覆盖,而addEventLinstener可以绑定多个监听器。html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> </head> <body> <button id="btn1">btn1</button> <button id="btn2">btn2</button> <script> let btn1 = document.getElementById('btn1') let btn2 = document.getElementById('btn2') btn1.onclick = () => { console.log('hello world1') } btn1.onclick = () => { console.log('前端加油站:http://www.jimmyxuexue.top:999/') } btn2.addEventListener('click', () => { console.log('公众号:Jimmy前端') }) btn2.addEventListener('click', () => { console.log('B站:Jimmyhao') }) </script> </body> </html><!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> </head> <body> <button id="btn1">btn1</button> <button id="btn2">btn2</button> <script> let btn1 = document.getElementById('btn1') let btn2 = document.getElementById('btn2') btn1.onclick = () => { console.log('hello world1') } btn1.onclick = () => { console.log('前端加油站:http://www.jimmyxuexue.top:999/') } btn2.addEventListener('click', () => { console.log('公众号:Jimmy前端') }) btn2.addEventListener('click', () => { console.log('B站:Jimmyhao') }) </script> </body> </html>事件队列的事件以什么顺序进行处理
给了一个例子,给一个元素添加mousemove和click事件并绑定了对应的监听器函数,事件的处理顺序是,当发生了一个事件之后,会将这个事件对应的监听器函数推入 事件队列 中,之后再去轮询 事件队列 ,从队首中取出对应的监听器执行,执行结束之后将这个监听器移出队列。
用户的鼠标移动和点击一定有先后的,先执行的事件会先被放入 事件队列 ,后执行的追加到队尾,主线程结束之后轮询队首,以此过程来保证执行的顺序不出错。
第二部分 理解函数
函数作为 JS 的一等公民,所以这本忍者书并没有像其他书籍一样先介绍对象,而是选择直接介绍函数。
回调函数并不是都是异步
回调函数 =》我们建立的函数会被其他函数在稍后的某个合适的时间点 ”再回来调用“
在过于因为使用:事件、网络请求、node 的一些 API 之后,我误认为所有的回调函数都是异步,其实不是这样的,我们先思考一个问题:
数组的 map 方法是异步的吗
先思考这个例子输出的结果是什么
js
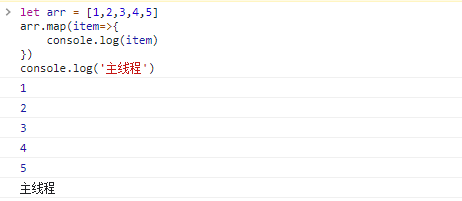
let arr = [1, 2, 3, 4, 5]
arr.map(item => {
console.log(item)
})
console.log('主线程')let arr = [1, 2, 3, 4, 5]
arr.map(item => {
console.log(item)
})
console.log('主线程')大家是否有被我误导到,我特意写一个主线程,会有人和我一样认为结果是:先输出主线程再输出 1,2,3,4,5 吗?
不怕大家笑话,这个在过去我一直认为它是异步的,因为这个事情我甚至一脸不屑的和公司的同事讨论过,我始终认为我是对的,结果一上代码测试结果我傻了,居然是同步的!!!这个一下子就颠覆了我的三观,原来自己学的一直都不到位。
好吧公布答案:
总结下来就是,回调函数并非都是异步的,当然也有人认为回调函数是异步的,只是这种回调函数并不是纯种的回调函数~好吧,我现在始终坚信,回调函数并非都是异步的。
存储函数
因为函数是一等公民,它也是对象,可以通过设置属性的方式进行存值,对应class语法也就是static的使用。
思考这个例子:我们需要维护一个回调函数集合,需要保证这个集合中肯定不会出现重复的回调函数。
抛开ES6的一些Set之类的 API,你会有什么样的解决思路的?我先说我的:将回调函数都存到一个数组中,每次存入都判断数组是否含有这个回调函数,如果含有就不存,不含有就存。代码如下:
js
let fnArr = []
let clickFn = () => {
console.log('点击事件的回调')
}
function addFn(fn) {
if (fnArr.includes(fn)) {
console.log('已经有了')
return
}
fnArr.push(fn)
console.log('加入成功')
}
addFn(clickFn) // 加入成功
addFn(clickFn) // 已经有了let fnArr = []
let clickFn = () => {
console.log('点击事件的回调')
}
function addFn(fn) {
if (fnArr.includes(fn)) {
console.log('已经有了')
return
}
fnArr.push(fn)
console.log('加入成功')
}
addFn(clickFn) // 加入成功
addFn(clickFn) // 已经有了这样写其实没什么毛病,但是性能相对较差,很简单,如果存储的数组量比较大了,那么每次查找是否有这个回调函数的时候就会花上比较多的时间,所以书中推荐了一种 忍者 的写法,所谓忍者,就是要把事情干的漂亮,而不是做到能用就好。
js
let store = {
nextIndex:1,
cache:{},
add(fn){
console.log(111,fn)
if(!fn.id){
fn.id = this.nextIndex++
this.cache[fn.id] = fn
console.log('存储上了')
return
}
console.log('已经有了')
}
}
function clickFn = ()=>{
console.log('点击事件回调函数')
}
store.add(clickFn) // 存储上了
store.add(clickFn) // 已经有了let store = {
nextIndex:1,
cache:{},
add(fn){
console.log(111,fn)
if(!fn.id){
fn.id = this.nextIndex++
this.cache[fn.id] = fn
console.log('存储上了')
return
}
console.log('已经有了')
}
}
function clickFn = ()=>{
console.log('点击事件回调函数')
}
store.add(clickFn) // 存储上了
store.add(clickFn) // 已经有了这样的写法真是太精妙了,巧妙的用到了函数 一等公民 的身份,利用函数作为对象形象存值,这样的写的好处在于就算已经存储了一万个回调函数,它的速度还是一样的快!!!这就是 忍者秘籍 !
果然,用函数和用好函数是两回事!😯
关于 this
在我作为 JavaScript 开发者前期一直困扰着我,但随着自己的积累,慢慢的已经懂得了在不同场景下 this 的指向问题,最后通过忍者秘籍的总结,算是彻底搞明白了,this 指向在以下情况下将有所不同:
- 作为一个函数调用(function),直接被调用
- 作为一个方法(method)被调用
- 作为一个构造函数(constructor),被实例化
- 通过
apply()、call()方法
作为函数被调用
当函数作为普通函数被调用时,也分为两种情况
- 在非严格模式下,this 指向
window - 在严格模式下,this 指向
undefined
js
function show() {
console.log('show:this', this)
}
show()
function strictShow() {
'use strict'
console.log('strictShow:this', this)
}
strictShow()function show() {
console.log('show:this', this)
}
show()
function strictShow() {
'use strict'
console.log('strictShow:this', this)
}
strictShow()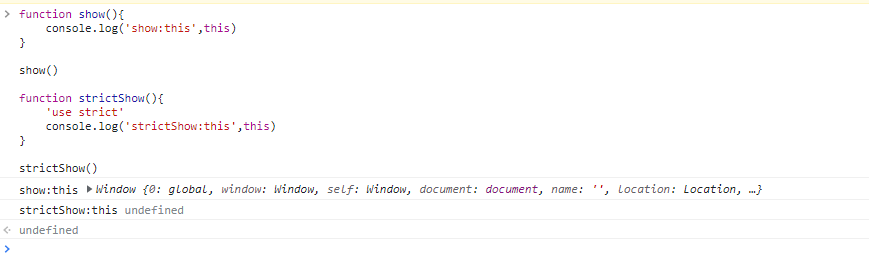
作为方法被调用
当函数时作为一个对象的某个属性时,我们更加习惯称呼这个函数为方法。
当通过方法被调用时,this 指向的时方法的拥有者。
js
let obj = {
wx: '公众号:Jimmy前端',
bilibili: 'Jimmyhao',
docs: 'http://www.jimmyxuexue.top:999/',
show1() {
console.log('show1_this', this)
},
show2: function () {
console.log('show2_this', this)
},
show3: () => {
console.log('show3_this', this)
},
}
obj.show1()
obj.show2()
obj.show3()let obj = {
wx: '公众号:Jimmy前端',
bilibili: 'Jimmyhao',
docs: 'http://www.jimmyxuexue.top:999/',
show1() {
console.log('show1_this', this)
},
show2: function () {
console.log('show2_this', this)
},
show3: () => {
console.log('show3_this', this)
},
}
obj.show1()
obj.show2()
obj.show3()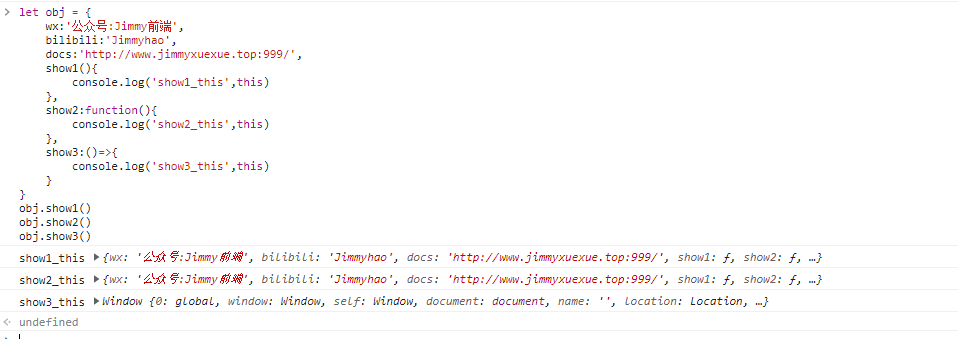
show1 的写法和 show2 的写法最终的效果是一样的,箭头函数的 this 指向的是它所处环境(它的上一级)的 this
作为构造函数使用
一个构造函数在new的过程主要发生了以下几件事:
- 创建一个空对象
- 该空对象作为 this 参数传递给构造函数,从而成为构造函数的上下文
- 新构造的对象作为
new运算符的返回值返回(在构造函数显示返回对象时会有例外,返回的显示返回的对象)
js
function User() {
this.wx = '公众号:Jimmy前端'
this.bilibili = 'Jimmyhao'
this.docs = '在线文档:http://www.jimmyxuexue.top:999/'
}
let Jimmy = new User()
console.log('jimmy', Jimmy)function User() {
this.wx = '公众号:Jimmy前端'
this.bilibili = 'Jimmyhao'
this.docs = '在线文档:http://www.jimmyxuexue.top:999/'
}
let Jimmy = new User()
console.log('jimmy', Jimmy)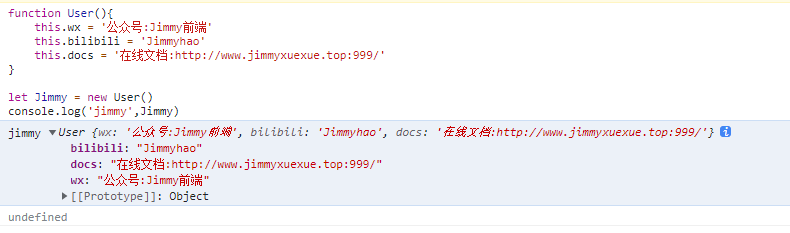
具体例外情况:
当构造函数本身返回的非对象时,this 走的还是正常初始化流程
jsfunction User() { this.wx = '公众号:Jimmy前端' this.bilibili = 'Jimmyhao' this.docs = '在线文档:http://www.jimmyxuexue.top:999/' return 1 } let Jimmy = new User() console.log('jimmy', Jimmy)function User() { this.wx = '公众号:Jimmy前端' this.bilibili = 'Jimmyhao' this.docs = '在线文档:http://www.jimmyxuexue.top:999/' return 1 } let Jimmy = new User() console.log('jimmy', Jimmy)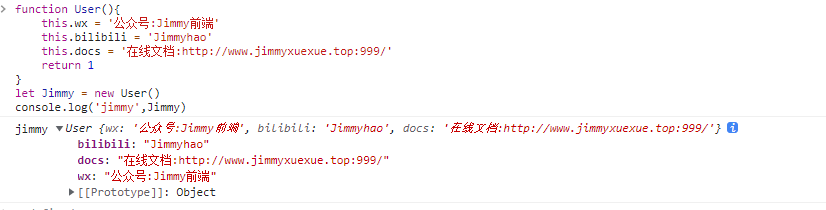
当构造函数返回的是对象时,会忽略掉初始化的流程,直接将返回值作为 new 的结果进行返回
jsfunction User() { this.wx = '公众号:Jimmy前端' this.bilibili = 'Jimmyhao' this.docs = '在线文档:http://www.jimmyxuexue.top:999/' return { name: 'Jimmyxuexue', age: 22, } } let Jimmy = new User() console.log('jimmy', Jimmy)function User() { this.wx = '公众号:Jimmy前端' this.bilibili = 'Jimmyhao' this.docs = '在线文档:http://www.jimmyxuexue.top:999/' return { name: 'Jimmyxuexue', age: 22, } } let Jimmy = new User() console.log('jimmy', Jimmy)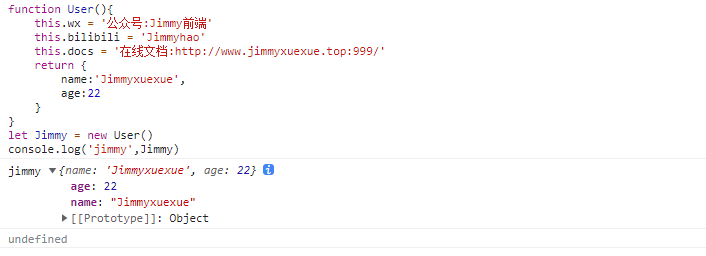
通过 call 和 apply 显示修改 this
call 和 apply 是可以显示修改 this 绑定的,这两个方法也是开发中非常常用的方法,如果有阅读他人源码时会发现使用的更加之多,二者的具体区别在于:
call 在修改 this 同时如果需要传参时单个单个传
jslet jimmy = { wx: '公众号:Jimmy前端', bilibili: 'Jimmyhao', docs: '在线文档:http://www.jimmyxuexue.top:999/', } function show(...args) { console.log(this, args) } show.call(jimmy, 1, 2, 3)let jimmy = { wx: '公众号:Jimmy前端', bilibili: 'Jimmyhao', docs: '在线文档:http://www.jimmyxuexue.top:999/', } function show(...args) { console.log(this, args) } show.call(jimmy, 1, 2, 3)
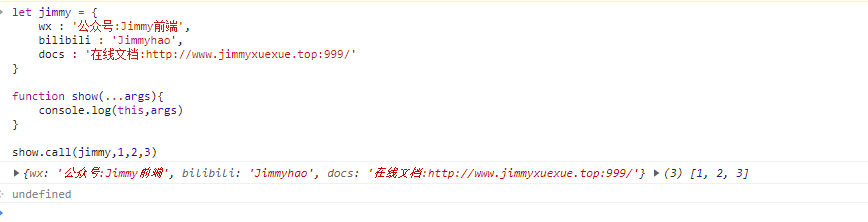
apply 在修改 this 同时如果需要传参传递的是一个数组
jslet jimmy = { wx: '公众号:Jimmy前端', bilibili: 'Jimmyhao', docs: '在线文档:http://www.jimmyxuexue.top:999/', } function show(...args) { console.log(this, args) } show.apply(jimmy, [1, 2, 3])let jimmy = { wx: '公众号:Jimmy前端', bilibili: 'Jimmyhao', docs: '在线文档:http://www.jimmyxuexue.top:999/', } function show(...args) { console.log(this, args) } show.apply(jimmy, [1, 2, 3])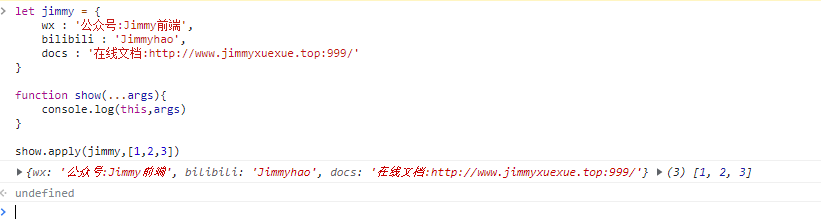
如果不传参二者基本无区别
在过去我总是会吧 call 和 apply 两个弄混淆,但是现在有个比较方法的记法:我们可以这样想,apply 比 call 字母更多,所以需要传递更大的东西,数组肯定比单个元素能放的东西更多,所以 apply 传参数是通过数组的方式!
总结下来 this 的指向我们其实只要参考这几个公式,基本就能够像忍者一样非常稳健的找出 this 的所在了.
理解闭包
闭包在 JS 这门语言中真的算是一个八股文级别的知识点,大部分开发者包括我在内,都对闭包这个词存在着恐惧,但是其实我们日常的开发中,无时无刻不在使用这闭包,只是我们不知道!所以闭包的概念是非常重要的。如我们日常频繁使用的回调函数,本质都是闭包!
如果没有闭包,事情将会变得非常复杂 ----- 如果么有闭包,事件处理和动画等包含回调函数的任务,他们的实现将会变得复杂很多。
简单的例子 - 利用闭包实现累加函数
js
function addFn() {
let count = 0
return () => {
return count++
}
}
let add = addFn()
console.log(add()) // 0
console.log(add()) // 1
console.log(add()) // 2function addFn() {
let count = 0
return () => {
return count++
}
}
let add = addFn()
console.log(add()) // 0
console.log(add()) // 1
console.log(add()) // 2以上便是闭包的一个非常简单的应用,大部分的函数,在执行之后都会因为 JS 的垃圾回收机制清空掉一些定义的变量,但是大家发现没有,这个例子的 count 值被神奇的记录下来了,而且还一直存在!!!
因为 js 使用的是 词法作用域 ,所谓词法作用域,也就是说一个函数或者变量的所在作用域是在书写函数的时候就定下来的,而不管这个函数具体在哪里执行,它都可以访问定义这个函数时候所在作用域的一些值。!!!
也正是因为函数是 JS 的一等公民,允许某个函数已返回值或者传参的形式传入,这就导致函数执行位置和定义函数时所在的位置不同,这时候,闭包就产生了!
使用闭包封装私有变量
原生的 JS 是不支持私有变量的,但是通过闭包,我们可以实现一个很接近的私有变量。
js
function User() {
let fans = 0
this.getFans = () => {
return fans
}
this.addFans = () => {
fans++
}
}
let jimmy = new User()
console.log(jimmy.fans) // undefined
jimmy.getFans() // 0function User() {
let fans = 0
this.getFans = () => {
return fans
}
this.addFans = () => {
fans++
}
}
let jimmy = new User()
console.log(jimmy.fans) // undefined
jimmy.getFans() // 0getFans 和 addFans 由于作用域规则它是可以访问函数内部的 fans 这个变量的,且只有在构造器内部才能访问它,我们通过使用 jimmy.getFans()本质上也是把函数在外部进行调用了,调用区域和定义的区域发生了差异,这时候闭包就会产生。并且只要这个函数存在,其内部的闭包就会一直存在!!!
回调函数本质上也是闭包
html
<div id="box">hello world</div>
<script>
function animate(elementId) {
let elem = document.getElementById(elementId)
let tick = 0
let timer = setInterval(() => {
if (tick < 100) {
elem.style.left = elem.style.top = tick + 'px'
tick++
} else {
clearInterval(timer)
}
}, 10)
}
animate('box1')
</script><div id="box">hello world</div>
<script>
function animate(elementId) {
let elem = document.getElementById(elementId)
let tick = 0
let timer = setInterval(() => {
if (tick < 100) {
elem.style.left = elem.style.top = tick + 'px'
tick++
} else {
clearInterval(timer)
}
}, 10)
}
animate('box1')
</script>这里 setInterval 的第一个参数传递的是一个回调函数,每次执行都会生成一个闭包,基于闭包,使得回调函数中可以访问到前面定义的 elem tick 这些变量。
也可以这么理解,回调函数的词法作用域能够访问 elem tick 这些变量的,所以回调函数无论被谁调用,在哪儿调用,都能访问到闭包这个区域的作用域上的变量。
如果没有闭包,我们的代码可能就要这么写
html
<div id="box">hello world</div>
<script>
function animate(elementId) {
let timer = setInterval(() => {
if (tick < 100) {
// 如果没有了闭包,说明没有了存储值的能力,所以回调函数每次使用都得重新获取一次值,效率非常之低效
let elem = document.getElementById(elementId)
let tick = 0
elem.style.left = elem.style.top = tick + 'px'
tick++
} else {
clearInterval(timer)
}
}, 10)
}
animate('box1')
</script><div id="box">hello world</div>
<script>
function animate(elementId) {
let timer = setInterval(() => {
if (tick < 100) {
// 如果没有了闭包,说明没有了存储值的能力,所以回调函数每次使用都得重新获取一次值,效率非常之低效
let elem = document.getElementById(elementId)
let tick = 0
elem.style.left = elem.style.top = tick + 'px'
tick++
} else {
clearInterval(timer)
}
}, 10)
}
animate('box1')
</script>总结
一道经典的闭包面试题:
闭包的作用
- 变量长期驻扎在内存当中(一般函数执行完毕,变量和参数会被销毁)
- 避免全局变量的污染
闭包的另外一面
- 闭包会记住作用域链的全部信息,因此我们不能过度使用。过度使用也会造成性能和效率问题
未来的函数:生成器
普通的函数,从头运行到尾,最多只会生成一个值。因为普通函数最多只有一个 return
过去我也看了蛮多 JS 类书籍,看到生成器这一块只是学习了它的 API,发现自己在工作中似乎是没有能够使用生成器函数的场景,使用到的还是基于生成器封装的async await之类的高级 API,以致于我在怀疑这一块需要深入了解吗?应付面试应该就可以了吧
但是!我看到了这本书上的一句对我来说“惊天动地”的一句话:“生成器经常被作为一种古怪不常用的语言特性,普通水平的程序员一般不会使用这个特性。”,这个普通水平好似千斤,重重的压在了我的心头。
生成器的基本知识
生成器在执行时并不会和普通函数一样执行函数内部的内容,生成器函数在执行之后会返回一个迭代对象。而迭代对象内部其实是有next()、throw()方法的。
迭代器:iterator
js
function* Book() {
console.log('comming!')
yield 'bilibili:Jimmyhao'
yield '公众号:Jimmy前端'
}
let jimmy = Book()
console.log('jimmy', jimmy)function* Book() {
console.log('comming!')
yield 'bilibili:Jimmyhao'
yield '公众号:Jimmy前端'
}
let jimmy = Book()
console.log('jimmy', jimmy)
我们通过 next 方法来迭代
js
jimmy.next() // {value: 'bilibili:Jimmyhao', done: false}
jimmy.next() // {value: '公众号:Jimmy前端', done: false}
jimmy.next() // {value: undefined, done: true}jimmy.next() // {value: 'bilibili:Jimmyhao', done: false}
jimmy.next() // {value: '公众号:Jimmy前端', done: false}
jimmy.next() // {value: undefined, done: true}迭代器每次执行都会返回一个含有迭代信息的对象,分别是值和是否结束的状态。
for-of 循环其实是遍历迭代器的,之所以数组可以使用 for-of,对象不能使用 for-of,是因为数组内部含有 iterator 属性,而对象没有
生成器的特点
每当生成器生成(迭代)一个值后,生成器就会非阻塞的挂起,随后耐心的等待下次迭代请求的到达
使用 yield 操作符将执行权交给另外一个生成器
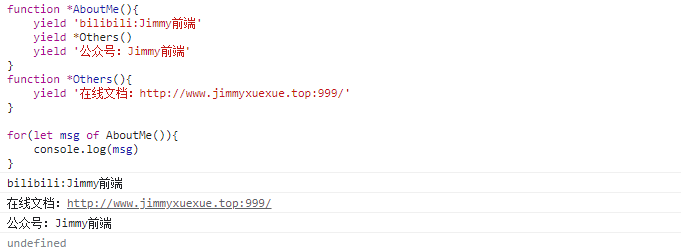
js
function* AboutMe() {
yield 'bilibili:Jimmy前端'
yield* Others()
yield '公众号:Jimmy前端'
}
function* Others() {
yield '在线文档:http://www.jimmyxuexue.top:999/'
}
for (let msg of AboutMe()) {
console.log(msg)
}function* AboutMe() {
yield 'bilibili:Jimmy前端'
yield* Others()
yield '公众号:Jimmy前端'
}
function* Others() {
yield '在线文档:http://www.jimmyxuexue.top:999/'
}
for (let msg of AboutMe()) {
console.log(msg)
}
在迭代器上使用 yield* 操作符,程序会跳转到另外一个生成器上执行,当然这个过程也是处于非阻塞的挂起执行
用生成器生成 ID 序列
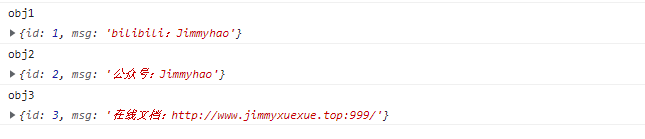
js
function* IdGenerator() {
let id = 0
while (true) {
yield ++id
}
}
const idIterator = IdGenerator()
let obj1 = { id: idIterator.next().value, msg: 'bilibili:Jimmyhao' }
let obj2 = { id: idIterator.next().value, msg: '公众号:Jimmyhao' }
let obj3 = {
id: idIterator.next().value,
msg: '在线文档:http://www.jimmyxuexue.top:999/',
}function* IdGenerator() {
let id = 0
while (true) {
yield ++id
}
}
const idIterator = IdGenerator()
let obj1 = { id: idIterator.next().value, msg: 'bilibili:Jimmyhao' }
let obj2 = { id: idIterator.next().value, msg: '公众号:Jimmyhao' }
let obj3 = {
id: idIterator.next().value,
msg: '在线文档:http://www.jimmyxuexue.top:999/',
}
第一眼看是不是也被惊艳到了!居然写出了while(true){}这种死循环的操作,在普通函数内部肯定不能这样写的,但是因为是生成器函数,每次请求都会非阻塞的挂起,所以这样写一点问题都没有。
而且这样写的另外一个好处是生成器中包含一个局部变量 id,代表 ID 计数器,这个 id 仅能生成器访问,所以不用担心会有人不小心修改其他代码而不小心改掉了 id 的数值,而且如果有另外的逻辑需要计数操作,只需要再次初始化一个迭代器就可以了。!
与生成器交互
我们可以与生成器进行交互,交互方式就是通过使用 next()方法迭代时进行传值,yield 负责接受值,如:next('Jimmy')
js
function* Message(name) {
const msg = yield 'hello' + name
if (msg === 'xuexue') {
console.log('msg is xuexue')
}
yield 'hello' + name
}
let jimmy = Message('jimmy')
jimmy.next()
jimmy.next('xuexue')function* Message(name) {
const msg = yield 'hello' + name
if (msg === 'xuexue') {
console.log('msg is xuexue')
}
yield 'hello' + name
}
let jimmy = Message('jimmy')
jimmy.next()
jimmy.next('xuexue')
这里如果没有理解 yield 交互的同学一定会很懵逼。第一次执行 next 的时候输出结果是 hellojimmy 这个没什么问题,不理解的地方主要是第二次执行next('xuexue')的时候,其实当 next 传值进行交互的时候,迭代位置的 yield 后面的整个内容看成形参,next 传的值作为实参,在这个例子中,yield ('hello'+name)中的 ('hello'+name)是形参,next('xuexue')中的 xuexue 是实参,所以会输出msg is xuexue
总结
生成器函数真的很有用,主要是它能无阻塞的挂起函数,等到合适的时候再恢复函数执行,执行结束之后继续挂起,这个太棒了,非常的适合 js 这种需要大量使用异步的语言。像 async await 就是它的语法糖。目前我还知道的就是 react 的状态管理 dva 就是需要手动写生成器函数。
第三部分 钻研对象
现在已经了解的函数的来龙去脉,下面将深入研究对象的特性!
使用 getter 和 setter 控制对象对象访问
getter 和 setter 可以使用多种方式进行定义
使用对象字面量定义
js
const userObj = {
names: ['Jimmy', 'xuexue', 'Jack'],
get firstUser() {
console.log('这里获取了这个数据,上报!')
return this.names[0]
},
set firstUser(user) {
if (typeof user !== 'string') {
console.error('类型错误')
return
}
this.namse[0] = user
},
}
console.log(obj.firstUser)
obj.firstUser = 123
console.log(obj.firstUser)const userObj = {
names: ['Jimmy', 'xuexue', 'Jack'],
get firstUser() {
console.log('这里获取了这个数据,上报!')
return this.names[0]
},
set firstUser(user) {
if (typeof user !== 'string') {
console.error('类型错误')
return
}
this.namse[0] = user
},
}
console.log(obj.firstUser)
obj.firstUser = 123
console.log(obj.firstUser)使用 Object.defineProperty 定义 getter 和 setter
以下这个是例子是定义私有变量的例子,有很多的框架的源码都会采用这种方式来定义私有变量的,所以这种命名方式看起来会特别的亲切。以上的例子还使用了闭包的概念。
js
function User() {
let _level = 0
Object.defineProperty(this, 'skillLevel', {
get: () => {
console.log('这里获取了这个数据,上报!')
return _level
},
set: value => {
if (typeof value !== 'number') {
console.log('类型错误')
return
}
_level = value
},
})
}function User() {
let _level = 0
Object.defineProperty(this, 'skillLevel', {
get: () => {
console.log('这里获取了这个数据,上报!')
return _level
},
set: value => {
if (typeof value !== 'number') {
console.log('类型错误')
return
}
_level = value
},
})
}计算属性、数据上报、类型校验
以上的两个例子我们分别使用 getter 和 setter 做到了 数据上报、数据校验,getter 的一个我认为更加重要作用是 计算属性 的应用。
js
const Person{
surname:'张',
subname:'翼德',
get fullName(){
return this.surname+this.subname
},
getFullName(){
return this.surname+this.subname
}
}const Person{
surname:'张',
subname:'翼德',
get fullName(){
return this.surname+this.subname
},
getFullName(){
return this.surname+this.subname
}
}以上的例子就非常好的能够展示 getter 作为计算属性时的好处,虽然 fullName 属性和 getFullName 方法最后返回的内容是一样的,但是一个是属性,另外一个是方法,而 fullname 顾名思义更像是属性,应该要使用的是计算属性的方式来进行定义的
使用代理控制访问
代理可以实现 getter 和 setter 的以上的所有内容,上面的 getter 和 setter 是属性级别的拦截,代理是对象级别的拦截!功能更加强大。
使用代理记录日志
js
let user = { name: 'Jimmy' }
function makeProxy(target) {
return new Proxy(target, {
get: (target, key) => {
console.log('这里获取了这个数据,上报!')
return target[key]
},
set: (target, key, value) => {
if (typeof value !== 'string') {
console.log('类型错误')
return
}
target[key] = value
},
})
}let user = { name: 'Jimmy' }
function makeProxy(target) {
return new Proxy(target, {
get: (target, key) => {
console.log('这里获取了这个数据,上报!')
return target[key]
},
set: (target, key, value) => {
if (typeof value !== 'string') {
console.log('类型错误')
return
}
target[key] = value
},
})
}以上这个例子实现了日志、类型检测,这个的好处在于这是个通用的监听,及时这个对象有 100 个 1000 个也是一样的,而如果是普通的、getter、setter 写法就得写出特别特别长的数据监听代码了。
使用代理检测性能
使用代理可以在不修改原函数代码的情况来,进行及评估一个函数的调用性能!
js
// 检测一个数是否是素数
function isPrime(number) {
if (number < 2) return false
for (let i = 2; i < number; i++) {
if (number % 2 === 0) return false
}
return true
}
let isPrimeProxy = new Proxy(isPrime, {
apply: (target, thisArg, args) => {
console.time('isPrime')
const result = target.apply(thisArg, args)
console.timeEnd('isPrime')
return result
},
})
isPrimeProxy(1299827)// 检测一个数是否是素数
function isPrime(number) {
if (number < 2) return false
for (let i = 2; i < number; i++) {
if (number % 2 === 0) return false
}
return true
}
let isPrimeProxy = new Proxy(isPrime, {
apply: (target, thisArg, args) => {
console.time('isPrime')
const result = target.apply(thisArg, args)
console.timeEnd('isPrime')
return result
},
})
isPrimeProxy(1299827)这个例子真是太酷了,过去用到的只有 get 和 set,知道有 apply,但是不知道原来还能这么进行使用。其实除了这个代理还有很多其他的拦截,在红宝书上有非常详细的介绍。
使用代理实现负数组索引
像 Python 这门语言,它的数组是支持负索引的,有负索引能够非常方便的放我们访问元素,我们也可以使用代理来简单的实现一下。
js
function createNegativeArrayProxy(array) {
if (!Array.isArray(array)) {
return new TypeError('不是数组类型')
}
return new Proxy(array, {
get: (target, index) => {
index = +index // 相对巧妙的转类型
return target[index < 0 ? target.length + index : index]
},
set: (target, index, value) => {
index = +index
return (target[index < 0 ? target.length + index : index] = val)
},
})
}
const users = ['Jimmy', 'xuexue', 'Jack']
let proxyUser = createNegativeArrayProxy(users)
console.log(users[-1])
console.log(proxyUser[-1])function createNegativeArrayProxy(array) {
if (!Array.isArray(array)) {
return new TypeError('不是数组类型')
}
return new Proxy(array, {
get: (target, index) => {
index = +index // 相对巧妙的转类型
return target[index < 0 ? target.length + index : index]
},
set: (target, index, value) => {
index = +index
return (target[index < 0 ? target.length + index : index] = val)
},
})
}
const users = ['Jimmy', 'xuexue', 'Jack']
let proxyUser = createNegativeArrayProxy(users)
console.log(users[-1])
console.log(proxyUser[-1])这个例子其实也可以使用 getter 和 setter 来实现的。通过代理也来实现一遍。
总结
使用 getter 和 setter 和代理可以做非常多事情,因为其相当于能够让我们在存值和取值的时候做一些事情,vue 的响应式的核心不就是通过这个实现的吗!
代理因为是 ES6 的东西,所以相对会有一些兼容性,但是还好,性能是比 Object.defineProperty 高很多的,但是因为创建了一些代理对象,所以和原生的比较性能还是会缺失一点,但是能让我们做更多的事情也值得。
数组
之所以把数组放到这里是因为 JS 中大部分东西皆是对象,数组也不例外。虽然这样会产生诸多不好的副作用,主要是性能方面,但是也有很好的方面,比如数组可以访问方法,与其他对象一样,这样使用起来就特别方便。
数组是对象的优势
C 版本
c
#include <stdio.h>
#include <math.h> // 涉及数学运算,就得引入一些其他库函数,Number
int main ()
{
printf("值 8.0 ^ 3 = %lf\n", pow(8.0, 3));
printf("值 3.05 ^ 1.98 = %lf", pow(3.05, 1.98));
return(0);
}#include <stdio.h>
#include <math.h> // 涉及数学运算,就得引入一些其他库函数,Number
int main ()
{
printf("值 8.0 ^ 3 = %lf\n", pow(8.0, 3));
printf("值 3.05 ^ 1.98 = %lf", pow(3.05, 1.98));
return(0);
}C 语言需要使用一些工具库必须单独引入,因为数组就是数组,本质上不是对象,所以不能像 JS 一样访问原型方法。
JavaScript 版本
js
let arr = [1,2,3,4,5]
console.log(arr.sort((a,b)=>a-b)let arr = [1,2,3,4,5]
console.log(arr.sort((a,b)=>a-b)因为 JS 数组本质上是对象,所以可以使用对象原型链上的一些属性和方法,这个就是优势!一些常用的好用的工具方法直接被封装到数组的构造函数原型上了,可以直接使用。
数组重要的方法
数组的方法越来越多,功能也越来越强大了,这里记录的只是单纯对于我来说,非常容易搞混乱的方法。
数组两端添加、删除元素
- push:在数组末尾添加元素
- unshift:在数组开头添加元素
- pop:在数组末尾弹出元素
- shift:在数组开头弹出元素
push=>pop 在尾部进行操作、unshift 和 shift 在数组头部操作,这个我比较容易混乱,会忘记哪个是添加哪个是删除,后面想了一个办法,和尾部操作一样,字母更多的那个是添加元素,更少的是删除元素。
从性能考虑,在数组头部操作更消耗性能还是尾部更消耗性能
这是一道经典的面试题,答案是在数组头部操作更消耗性能,因为数组在内存中存储的位置是顺序存储的,如果是头部发生改变,那么剩下的元素的位置都会发生调整,而如果是尾部则不会发生调整。
在数组任意位置添加、删除元素
这里主要使用的是数组的另外一个强大的方法splice,该方法会修改原数组,且会将删除的内容以数组的形式返回!
单传递两个参数,代表删除!
jslet users = ['jimmy', 'xuexue', 'jack', 'henry'] let removeItems = users.splice(1, 2) console.log(removeItems) // ['xuexue', 'jack'] console.log(users) // ['jimmy', 'henry']let users = ['jimmy', 'xuexue', 'jack', 'henry'] let removeItems = users.splice(1, 2) console.log(removeItems) // ['xuexue', 'jack'] console.log(users) // ['jimmy', 'henry']以上这个例子表示的是,从数组索引为 1 的位置开始函数,删除两个元素!
当传递多个参数,可以表示插入
jslet users = ['jimmy', 'xuexue', 'jack', 'henry'] let removeItems = users.splice(1, 2, 'makbaka', 'woxodixi') console.log(removeItems) // ['xuexue', 'jack'] console.log(users) // ['jimmy', 'makbaka', 'woxodixi', 'henry']let users = ['jimmy', 'xuexue', 'jack', 'henry'] let removeItems = users.splice(1, 2, 'makbaka', 'woxodixi') console.log(removeItems) // ['xuexue', 'jack'] console.log(users) // ['jimmy', 'makbaka', 'woxodixi', 'henry']以上这个例子表示的是,从数组索引为 1 的位置开始函数,删除两个元素!之后再插入 makbaka、woxodixi 这两个元素。这个就有一些细节了!
- removeItems 只会返回被删除的元素,插入的元素不会添加进去
- 如果是在中间插入,那么之后的元素的索引会往后移动。如:henry 就会变成数组的最后一个
Map
map 通常称为字典。当我们需要处理一类映射关系集合时,在 JS 中、Map 才是最佳的使用工具。
别把对象当作 Map
比如我们需要处理一个翻译字典,我的第一想法也是使用对象,因为对象用起来太方便和简单了,但是这会有问题的!!!
会触发原型链查找
js
let dictionaries = {
ja: {
'Ninjas for hire': '一段日文',
},
zh: {
'Ninjas for hire': '忍者出租',
},
}
console.log(dictionaries.ja['constructor']) // ƒ Object() { [native code] }let dictionaries = {
ja: {
'Ninjas for hire': '一段日文',
},
zh: {
'Ninjas for hire': '忍者出租',
},
}
console.log(dictionaries.ja['constructor']) // ƒ Object() { [native code] }问题已经很明显的暴露出来了,我们访问ja对象里面不存在的constructor这个英文对应的翻译,按道理字典中没有这个文字应该返回undefind才是理想情况,但是却返回了ƒ Object() { [native code] }。这个是因为constructor是原型对象的属性之一,所以会到原型链上寻找,这个就是罪魁祸首。
key 会被静默转成字符串
html
<div id="first"></div>
<div id="second"></div>
<script>
let first = document.getElementById('first')
let second = document.getElementById('second')
let map = {}
map[first] = { data: 'firstElement' }
map[second] = { data: 'secondElement' }
console.log(map[first]) // {data: 'secondElement'}
</script><div id="first"></div>
<div id="second"></div>
<script>
let first = document.getElementById('first')
let second = document.getElementById('second')
let map = {}
map[first] = { data: 'firstElement' }
map[second] = { data: 'secondElement' }
console.log(map[first]) // {data: 'secondElement'}
</script>map[first]返回的怎么不是{data:'firstElement'}呢?我们再打印一下 map 会发生,map 存的实际上是
js
{
[object HTMLDivElement]: {data: 'secondElement'}
}{
[object HTMLDivElement]: {data: 'secondElement'}
}原来不管是存 first 还是 second,对象都会把 key 转正字符串,DOM 对象会被静默的转成[object HTMLDivElement],所以本质上是存到同一个 key 上了。这就是对象的一个缺点。
争对以上的两个缺点,所以 map 就能完美的解决。
- map 支持对象类型作为 key
- map 封装 has 方法,不会触发原型链的查找
js
let map = new Map()
const currentUrl = location.href
const firstLink = new URL(currentUrl)
const secondLink = new URL(currentUrl)
map.set(firstLink, { text: 'first' })
map.set(secondLink, { text: 'scond' })
console.log(map.has('constructor')) // false
console.log(map.get(firstLink)) //{text: 'first'}
console.log(map.get(secondLink)) //{text: 'scond'}let map = new Map()
const currentUrl = location.href
const firstLink = new URL(currentUrl)
const secondLink = new URL(currentUrl)
map.set(firstLink, { text: 'first' })
map.set(secondLink, { text: 'scond' })
console.log(map.has('constructor')) // false
console.log(map.get(firstLink)) //{text: 'first'}
console.log(map.get(secondLink)) //{text: 'scond'}以上的例子可以看出:
- 没有触发原型链查找
- 支持了对象作为 key 进行存储
Set
map 是对标对象的一种类型,set 是对标数组的一种类型,set 是一种集合,集合中的每个元素都是唯一的。set 也能避免访问原型链的风险。
并集、交集、差集
使用 set 可以非常快速的实现并集、交集、差集的操作!
并集
js
let user1 = ['jimmy', 'xuexue', 'henry']
let user2 = ['henry', 'Jack']
const warriors = new Set([...user1, ...user2])
console.log(warriors) // Set(4) {'jimmy', 'xuexue', 'henry', 'Jack'}let user1 = ['jimmy', 'xuexue', 'henry']
let user2 = ['henry', 'Jack']
const warriors = new Set([...user1, ...user2])
console.log(warriors) // Set(4) {'jimmy', 'xuexue', 'henry', 'Jack'}交集
js
let user1 = new Set(['jimmy', 'xuexue', 'henry'])
let user2 = new Set(['henry', 'Jack'])
const intersection = new Set([...user1].filter(user => user2.has(user)))
console.log(intersection) // Set(1) {'henry'}let user1 = new Set(['jimmy', 'xuexue', 'henry'])
let user2 = new Set(['henry', 'Jack'])
const intersection = new Set([...user1].filter(user => user2.has(user)))
console.log(intersection) // Set(1) {'henry'}差集
js
let user1 = new Set(['jimmy', 'xuexue', 'henry'])
let user2 = new Set(['henry', 'Jack'])
const intersection = new Set([...user1].filter(user => !user2.has(user)))
console.log(intersection) // Set(2) {'jimmy', 'xuexue'}let user1 = new Set(['jimmy', 'xuexue', 'henry'])
let user2 = new Set(['henry', 'Jack'])
const intersection = new Set([...user1].filter(user => !user2.has(user)))
console.log(intersection) // Set(2) {'jimmy', 'xuexue'}总结
map 和 set 是更加优秀的类型,避免了一些相对恶心的场景出现,而且也封装了更加优雅的 API,因为其是集合类型,所以是支持 for-of 迭代的!
这个是属于一定要掌握的内容,很多大神已经在使用了,比如 vue3 的源码,都是用到了 set 和 map 这些数据类型了。
正则表达式
正则表达式是一个效率神器,虽然很多开发者(包括我在内)不用正则表达式额能顺利的完成工作,诚然,如果不适用正则表达式,很多情况下就无法使用 JS 优雅的解决问题。JS 也是每一个忍者特工的 必备武器!
正则其实也是体验一个程序员编程能力的,我们可以发现哪些大牛,尤其是年龄相对大一点的程序员,他们的正则能力都是十分扎实的,所以正则一定得学好,不说特别牛吧,起码得会用,不要每次都去查文档再用。
为什么要使用正则
一个 demo,快速理解为什么要使用正则:
验证美国邮政编码,格式为:99999-9999。
不使用正则
js
function isThisZipCode(candidate) {
if (typeof candidate !== 'string' || candidate.length != 10) return false
for (let n = 0; n < candidate.length; n++) {
let c = candidate[n]
switch (n) {
case 0:
case 1:
case 2:
case 3:
case 4:
case 6:
case 7:
case 8:
case 9:
if (c < 0 || c > 9) {
return false
}
break
case 5:
if (c !== '-') {
return false
}
break
}
}
return true
}
console.log(isThisZipCode('99999-9999'))function isThisZipCode(candidate) {
if (typeof candidate !== 'string' || candidate.length != 10) return false
for (let n = 0; n < candidate.length; n++) {
let c = candidate[n]
switch (n) {
case 0:
case 1:
case 2:
case 3:
case 4:
case 6:
case 7:
case 8:
case 9:
if (c < 0 || c > 9) {
return false
}
break
case 5:
if (c !== '-') {
return false
}
break
}
}
return true
}
console.log(isThisZipCode('99999-9999'))使用正则
js
function isThisZipCode(candidate) {
return /^\d{5}-\d{4}$/.test(candidate)
}
console.log(isThisZipCode('99999-999'))function isThisZipCode(candidate) {
return /^\d{5}-\d{4}$/.test(candidate)
}
console.log(isThisZipCode('99999-999'))两者一对比,区别出来了吧,使用正则我们能够使用极其少的代码非常优雅的实现我们想要的效果,这就是忍者的操作!
修饰符
| 符号 | 含义 |
|---|---|
| i | 不区分大小写 |
| g | 全局匹配(默认匹配到一个就会终止) |
| m | 多行匹配(这个对 textarea 特别有用) |
| y | 粘性匹配(试图从最后一个匹配的位置开始) |
| u | 允许使用 unicode 转义符 |
术语&操作符
精确匹配、匹配字符集、起止符号
| 符号 | 含义 |
|---|---|
| [] | 字符集操作符号,如[abc]表示匹配 abc 中任意一个 |
| [^] | 反向字符操作符号,如[^abc]表示匹配除了 abc 的任意字符 |
| [a-z] | 表示匹配字母 a 到 z 的字符。也可以是[1-9] [A-Z] |
| ^ | 开始符号,如/^test/表示匹配 test 开头的字符 |
| $ | 结束符号,如/test$/表示匹配 test 结束的的字符 |
| | | 表示或,如/a|b/表示匹配 a 或 b |
重复匹配
| 符号 | 含义 |
|---|---|
| ? | 出现 0 次或一次 |
| + | 出现 1 次或多次 |
| * | 出现 0 次或多次 |
| {} | 自定义重复次数,如{2,10}表示出现 2 次到 10 次、{4}表示出现 4 次、{4,}表示至少出现 4 次 |
贪婪模式与非贪婪模式
这些重复匹配的运算符都是可以支持贪婪和非贪婪模式的,默认是贪婪模式的。
贪婪:尽可能匹配最多的东西。
在运算符后面添加一个 **?**即可开启非贪婪模式。
如字符串 aaa 使用/a+/进行匹配会将三个 a 都匹配到,而我们使用/a+?/可以禁止贪婪模式,只会匹配到一个 a
预定字符集与元字符
| 符号 | 含义 |
|---|---|
| \t | 水平制表符号。即 tab |
| \b | 空格 |
| \r | 回车符 |
| \f | 换页符 |
| \h | 换行符 |
| . | 匹配除换行符以外的任意字符 |
| \d | 匹配任意十进制数字,即[0-9] |
| \D | 匹配除了十进制数字以外的任意字符,即[^0-9] |
| \w | 匹配任意字母、数字、下划线,即[0-9a-zA-Z_] |
| \W | 匹配除了字母、数字、下划线以外的字符,即[^0-9a-zA-Z_] |
| \s | 匹配任意空白符(包括空格、制表、换页符等等) |
| \S | 匹配除了空白符以外的任意字符 |
| \b | 匹配单词边界 |
| \B | 匹配非单词边界(单词内部) |
捕获匹配的片段
一个很好的例子:
利用正则捕获 CSS 的 transform 属性
html
<div id="square" style="transform: translateY(15px)"></div>
<script>
function getTranslateY(element) {
const transformValue = element.style.transform
if (transformValue) {
const match = transformValue.match(/translateY\(([^\]]+)\)/)
return match ? match[1] : ''
}
return ''
}
let square = document.getElementById('square')
console.log(getTranslateY(square)) // 15px
</script><div id="square" style="transform: translateY(15px)"></div>
<script>
function getTranslateY(element) {
const transformValue = element.style.transform
if (transformValue) {
const match = transformValue.match(/translateY\(([^\]]+)\)/)
return match ? match[1] : ''
}
return ''
}
let square = document.getElementById('square')
console.log(getTranslateY(square)) // 15px
</script>match 方法是 String 对象的方法,match 的返回的结果是一个数组,其数组的第一项是匹配的整个内容,第二个是原子组(括号分组)匹配到的内容。
咋一看/translateY\(([^\]]+)\)/好像很复杂,但是拆开看还好,首先就是 translateY 这个是全量匹配,之后就是原子组中的内容,这里使用到了\(\)来转义括号,内部再进行匹配除了右括号的内容,就可以获取到内部的值了!
match 方法在全局模式和非全局模式下的区别
上个例子知道了 match 方法非常的好用,但是也说了 match 的返回的结果是一个数组,其数组的第一项是匹配的整个内容,第二个是原子组(括号分组)匹配到的内容。但是其实这个是非全局匹配下的情况才是这样返回的,如果是全局匹配(加了 g),其返回任然是一个数组,且返回全部匹配结果,不会有原子组捕获的结果!
非全局模式
jsconst html = "<div class='test'><b>hello</b> <i>world!</i></div>" const reg1 = /<(\/?)(\w+)([^>]*?)>/ const result = html.match(reg1) console.log(result[0]) // <div class='test'> console.log(result[1]) // ''空 console.log(result[2]) // div console.log(result[3]) // class='test'const html = "<div class='test'><b>hello</b> <i>world!</i></div>" const reg1 = /<(\/?)(\w+)([^>]*?)>/ const result = html.match(reg1) console.log(result[0]) // <div class='test'> console.log(result[1]) // ''空 console.log(result[2]) // div console.log(result[3]) // class='test'因为是非全局模式,所以会这个正则匹配到
<div class='test'>就会结束匹配,match 返回的数组第一项的结果就是这个值。因为正则有三个原子组,所以接下来的数组的第一项、第二项、第三项就是原子组匹配的内容。
这个是在非全局模式,所以 match 的结果会对原子组的匹配做一次收集!!!!
全局模式
htmlconst html = " <div class="test"><b>hello</b> <i>world!</i></div> "; const reg1 = /<(\/?)(\w+)([^>]*?)>/g; const result = html.match(reg1); console.log(result[0]); // <div class="test"> console.log(result[1]); // <b> console.log(result[2]); // </b> console.log(result[3]); // <i> console.log(result[4]); // </i> console.log(result[5]); // </div>const html = " <div class="test"><b>hello</b> <i>world!</i></div> "; const reg1 = /<(\/?)(\w+)([^>]*?)>/g; const result = html.match(reg1); console.log(result[0]); // <div class="test"> console.log(result[1]); // <b> console.log(result[2]); // </b> console.log(result[3]); // <i> console.log(result[4]); // </i> console.log(result[5]); // </div>因为是全局模式,所以 match 不会匹配到一个就停止匹配,而是会继续的向下进行匹配,这个模式下 match 的结果是一个数组,数组的每一项代表的就是全局匹配到的每一项。就不会有非全局模式下对原子组内容的收集了!!!
exec
有时候我们就想在全局匹配模式下又能收集原子组的匹配内容,这时候就可以使用正则 exex 方法,该方法会保留上次调用的结果,每次调用都会是下次匹配以及捕获的结果。
js
const html = "<div class='test'><b>hello</b> <i>world!</i></div>"
const reg1 = /<(\/?)(\w+)([^>]*?)>/g
let match,
nums = 0
while ((match = reg1.exec(html)) !== null) {
console.log(match)
console.log(match[0])
console.log(match[1])
console.log(match[2])
console.log(match[3])
nums++
}
console.log('总数', nums) // 6const html = "<div class='test'><b>hello</b> <i>world!</i></div>"
const reg1 = /<(\/?)(\w+)([^>]*?)>/g
let match,
nums = 0
while ((match = reg1.exec(html)) !== null) {
console.log(match)
console.log(match[0])
console.log(match[1])
console.log(match[2])
console.log(match[3])
nums++
}
console.log('总数', nums) // 6反向引用
使用反向引用快速实现单词的转写
js
let str = 'fontFamily'
console.log(str.replace(/([A-Z])/g, '-$1').toLocaleLowerCase()) //font-familylet str = 'fontFamily'
console.log(str.replace(/([A-Z])/g, '-$1').toLocaleLowerCase()) //font-family在使用 replace 方法时,我们使用$1或者\1,就可以表示第一个原子组匹配到的内容,这个就是反向引用,非常优雅的就能解决问题!
未捕获的分组
因为原子组在使用的时候一般情况下都会帮我们收集一次捕获内容,有时候我们并不想收集捕获内容,因为这个收集的过程也是会消耗性能的,所以我们可以使用(?:)的形式组织模式收集的方式:
正常使用
js
let pattern = /((ninja-)+)sword/
let str = 'ninja-ninja-sword'
let result = str.match(pattern)
console.log(result.length) // 3
console.log(result[0]) // ninja-ninja-sword
console.log(result[1]) // ninja-ninja-
console.log(result[2]) // ninja-let pattern = /((ninja-)+)sword/
let str = 'ninja-ninja-sword'
let result = str.match(pattern)
console.log(result.length) // 3
console.log(result[0]) // ninja-ninja-sword
console.log(result[1]) // ninja-ninja-
console.log(result[2]) // ninja-使用(?:)禁止分组
js
let pattern = /((?:ninja-)+)sword/
let str = 'ninja-ninja-sword'
let result = str.match(pattern)
console.log(result.length) // 2
console.log(result[0]) // ninja-ninja-sword
console.log(result[1]) // ninja-ninja-let pattern = /((?:ninja-)+)sword/
let str = 'ninja-ninja-sword'
let result = str.match(pattern)
console.log(result.length) // 2
console.log(result[0]) // ninja-ninja-sword
console.log(result[1]) // ninja-ninja-两者的区别就在于,其内层的圆括号编程了一个被动表达式,只有外层的圆括号会被分组和创建捕获!
案例
js
let reg = /(?:ninja)-(trick)?-\1/
let str1 = 'ninja-trick-trick'
let str2 = 'ninja-'
let str3 = 'ninja-trick-ninja'
console.log(reg.test(str1)) // true
console.log(reg.test(str2)) // false
console.log(reg.test(str3)) // falselet reg = /(?:ninja)-(trick)?-\1/
let str1 = 'ninja-trick-trick'
let str2 = 'ninja-'
let str3 = 'ninja-trick-ninja'
console.log(reg.test(str1)) // true
console.log(reg.test(str2)) // false
console.log(reg.test(str3)) // false这个例子就特别好理解了,\1表示和第一个分组的内容取一样的内容,按道理第一个分组应该是(?:ninja),但是这个括号的内容是(?:)也就是屏蔽分组捕获,所以最终这个\1表示的是(trick)。
其他案例
将
foo=1&foo=2&blah=a&foo=3&blah=b转换为foo=1,2,3&blah=a,bjsfunction compres(source) { const keys = {} source.replace(/([^=&]+)=([^&]*)/g, (full, key, value) => { keys[key] = [keys[key] ? keys[key] + ',' : ''] + value return '' }) const result = [] for (let key in keys) { result.push(key + '=' + keys[key]) } return result.join('&') } console.log(compres('foo=1&foo=2&blah=a&foo=3&blah=b')) // foo=1,2,3&blah=a,bfunction compres(source) { const keys = {} source.replace(/([^=&]+)=([^&]*)/g, (full, key, value) => { keys[key] = [keys[key] ? keys[key] + ',' : ''] + value return '' }) const result = [] for (let key in keys) { result.push(key + '=' + keys[key]) } return result.join('&') } console.log(compres('foo=1&foo=2&blah=a&foo=3&blah=b')) // foo=1,2,3&blah=a,b
总结
正则的内容真的太多了,学起来并不是一两天甚至几个月的事情,主要这玩意儿涉及的一些知识点真的很多,稍微用不到就会忘记,真如我是看了至少三遍的正则,还是不会用,所以我的目标是以后在可以使用正则的场景都逼自己使用正则,而不是停留在舒适区使用其他方式完成需求。
代码模块化
组织良好的代码总是比庞大的代码更容易理解和维护,所以这个就诞生了模块化,相对于前端来说我们平时可能更加注重 组件化 但是我们在实现组件化的代码的时候,也在潜移默化的写研究的 模块化 在想着,哪里的代码能进行封装,方便下次复用......
模块是比对象和函数更大的代码单元,可以极大的提高应用程序的开发效率。
历史问题
在 ES6 之前 JS 官方并没有给出模块化的技术,但是因为模块化实在是太重要了,一些大牛人员就自己基于 JS 的 对象、立即执行函数、闭包 开发出了模块化技术,AMD 和 CommonJS 就是典型的解决方案!
自己实现一个模块
前面说了,我们可以自己基于 对象、立即执行函数、闭包 实现一个模块!
js
const mouseCounterModule = (function () {
let numCount = 0
const handleClick = () => {
alert(++numCount)
}
return {
countClick: () => {
document.addEventListener('click', handleClick)
},
}
})()const mouseCounterModule = (function () {
let numCount = 0
const handleClick = () => {
alert(++numCount)
}
return {
countClick: () => {
document.addEventListener('click', handleClick)
},
}
})()以上就是我们创建了一个模块,因为立即执行函数,返回了一个对象,对象引用了一个函数内部的方法,形成了闭包,所以立即执行函数内部的值会一直存在,不会被外界的一些变量所污染。
我们立即执行函数返回的那个对象,就是模块的接口
扩展模块(模块之间相互使用)
js
const mouseCounterModule = (function () {
let numCount = 0
const handleClick = () => {
alert(++numCount)
}
return {
countClick: () => {
document.addEventListener('click', handleClick)
},
}
})()
// 这下面的代码时重点!!!!
;(function (module) {
let numScroll = 0
const handleScroll = () => {
alert(++numScroll)
}
module.countScroll = handleScroll
})(mouseCounterModule)
mouseCounterModule.countScroll()const mouseCounterModule = (function () {
let numCount = 0
const handleClick = () => {
alert(++numCount)
}
return {
countClick: () => {
document.addEventListener('click', handleClick)
},
}
})()
// 这下面的代码时重点!!!!
;(function (module) {
let numScroll = 0
const handleScroll = () => {
alert(++numScroll)
}
module.countScroll = handleScroll
})(mouseCounterModule)
mouseCounterModule.countScroll()我们使用扩展模块也是需要使用到 对象、立即执行函数、闭包 因为 module 本身就是对象,所以可以给模块上添加属性来实现扩展,之所以要使用闭包和立即执行函数是为了防止变量的全局污染!!!
我们可以看到自己写的模块其实也有缺点:
- 扩展方法是在完全独立的作用域中扩展的,闭包之间无法相互访问
- 并不是基于文件的,也是不好维护。
AMD
AMD 的 A 代表的是async,所以 AMD 是加载模块是异步加载的,因为这个,所以 AMD 是明确基于浏览器的,因为浏览器加载文件一定要是异步的,如果是同步加载必定会造成或多或少的阻塞。
AMD 代码
js
define('mouseCountrModule', ['jQuery'], $ => {
let numClick = 0
const handleClick = () => {
alert(++numClick)
}
return {
countClick: () => {
$(document).on('click', handleClick)
},
}
})define('mouseCountrModule', ['jQuery'], $ => {
let numClick = 0
const handleClick = () => {
alert(++numClick)
}
return {
countClick: () => {
$(document).on('click', handleClick)
},
}
})AMD 提供 define 函数用于定义一个模块,并传递三个参数:
- 模块名称
- 依赖的其他模块
- 初始化模块的工厂函数
工厂函数会在依赖其他的模块都下载好之后执行,所以工厂函数的形参是能够拿到其他模块导出的变量的。
AMD 具有以下的优点:
- 移动依赖处理,无需考虑依赖加载的顺序
- 异步加载,避免阻塞
- 在同一个文件中可以定义多个模块
CommonJS
CommonJS 设计面向的是通用 JS 环境,普遍的被使用在 NodeJS 中,有 NodeJS 开发经验的同学肯定知道,CommonJS 模块是基于文件的,且文件是同步加载的(也因为这个所以不适合用在浏览器,会发生阻塞)但是在服务端这个是一点问题都没有。
js
// a.js
const $ = require('jQuery')
let numClick = 0
const handleClick = () => {
alert(++numClick)
}
module.exports = {
countClick: () => {
$(document).on('click', handleClick)
},
}
// b.js
const mouseClickModule = require('a.js')
mouseClickModule.countClick()// a.js
const $ = require('jQuery')
let numClick = 0
const handleClick = () => {
alert(++numClick)
}
module.exports = {
countClick: () => {
$(document).on('click', handleClick)
},
}
// b.js
const mouseClickModule = require('a.js')
mouseClickModule.countClick()CommonJS 具有以下优势:
- 语法简单。只要定义
modulemodule.exportsexports即可,完全可以自己手动实现一个简单的版本 - Node.JS 的默认模块格式,所以我们可以使用 npm 市场上众多的包
UMD
umd 的语法有点复杂,它是同时支持 amd 和 CommonJS 的,这个在我学习 webpack 打包项目的时候有专门的一个配置项是配置这个打包之后的格式,可以设置成 umd。
ESM
ES6 的模块结合了 AMD 和 CommonJS 的优点,具体如下:
- 与 CommonJS 类似,模块化语法相对简单,也是基于文件
- 与 AMD 类似,ES6 模块是支持异步加载的
这个模块化的语法比 CommonJS 还重要!真正是前端程序员接触最多的,但是因为使用起来也比较简单,相信大家也都会,就简单的带过了。
js
// a.js
import $ form 'jQuery'
let numClick = 0
const handleClick = ()=>{
alert(++numClick)
}
export handleClick
// b.js
import {handleClick} from 'a.js'
handleClick()// a.js
import $ form 'jQuery'
let numClick = 0
const handleClick = ()=>{
alert(++numClick)
}
export handleClick
// b.js
import {handleClick} from 'a.js'
handleClick()ESM 也是有一些细节的
当导入或者导出的变量或者方法名字太长,可以使用
as进行改名jsimport { aaaa as b } from 'a.js' // --------------------------- export { sayHi as sayHello }import { aaaa as b } from 'a.js' // --------------------------- export { sayHi as sayHello }export default是默认导出,引入默认导出的对象可以自定义名字export是具名导出,名字一定要一样,且这个会有语法提示,很好用!
总结
模块化现在开发已经离不开,基本都是 ESM,很容易上手,就随便带过了,不过过去我清湖 AMD 具体是什么,还有 UMD 还是有收获的!!!
第四部分 洞悉浏览器
对于我来说使用的最多的工具出了写代码的 IDE,那就是浏览器了,虽然现在有了 Node.js,但是浏览器是大多数 JS 应用最常被执行的环境了。所以浏览器的一定要玩明白了。
DOM 操作
通过 JS 是可以快速的操作 DOM 的,可能是面试题做多了或者说是自己也进步了一点,现在一想到 DOM 操作,脑子中想到的不是各种 API,而是 性能 ,DOM 的操作都是消耗性能的。
一些第三方优秀的框架之所以使用的人多很大一方面就是他们对 DOM 的操作做到了极致!如 Vue 使用 Vnode,react 的虚拟 DOM,都是会进行比对,然后找出不同的地方,再在合适的时候进行指定的 DOM 更新操作而不是全量的 DOM 更新!
操作不当会引发性能问题
为什么我们修改文本时推荐使用textContent、而不是innerHTML?好像当修改文本时两个都能正确的操作,但是innerHTML做的事情更多,以下例子可见:
将 HTML 字符串转成 DOM
html
<option>Jimmy</option>
<option>xuexue</option>
<table /><option>Jimmy</option>
<option>xuexue</option>
<table />当我们要插入这代码的时候,会先进行预解析,将明显的错误给改掉,这里的明显的错误有:
- option 标签必须包裹在 select 标签内
- table 标签不是自闭合标签
所以真正在插入的时候发现页面没有问题,浏览器会解决掉这些问题,这个就是个耗时的时间,所以我们在写的时候一定要确保内容是没有问题的。
使用 DOMfragment
当我们需要批量执行一些插入类型的 DOM 操作时,可以使用文档碎片对象来进行操作,其相当于时提供了一个临时存储 DOM 节点的容器,因为其存在内存中不在页面中,所以做一些操作的时候并不会引起回流、重绘之类的东西。
这个操作是节约性能的一个大杀器,vue3 的源码就有使用到这个操作。
DOM 特性以及属性
理解了这个之后,可以非常快速的获取 DOM 的属性
html
<div data-dz="xuexue"></div>
<script>
const div = document.querySelector('div')
div.setAttribute('id', 'jimmy')
console.log(div.id) // jimmy
console.log(div.getAttribute('id')) // jimmy
console.log(div['data-dz']) // undefined
console.log(div.getAttribute('data-dz')) // xuexue
</script><div data-dz="xuexue"></div>
<script>
const div = document.querySelector('div')
div.setAttribute('id', 'jimmy')
console.log(div.id) // jimmy
console.log(div.getAttribute('id')) // jimmy
console.log(div['data-dz']) // undefined
console.log(div.getAttribute('data-dz')) // xuexue
</script>我们会发现,我们获取 div 的 id 可以使用:
- div.getAttribute('id')
- div.id
以上两个方式都可以获取,我们会发现使用div.id是更加快速的获取。
但是一些自定义的属性我们是不可以直接通过点的方法来获取的,这就必须得使用getAttribute来进行获取了。
注意
在 HTML5 中,为了遵循规范,建议使用data-作为自定义属性的前缀,这是很好的定义方式,也可以区分是自定义的属性还是原生的属性。
样式特性
我们使用 JS 操作 DOM 的时候很多情况下都是会对 DOM 的一些样式进行操作,如一些通过 JS 操作的动画都是获取元素的 style 属性,而 style 属性就是 DOM 属性上最复杂的一个,因为它不是字符串,而是一个对象。
因为 style 属性是一个对象,所以如我们获取颜色可以DOM.style.color,但是名字并不是全部都可以按照 CSS 属性名进行获取的。
获取
font-size属性:DOM.style.fontSize而不是DOM.style.font-size,这是个细节,css 属性中有使用-的属性对应到 JS 的 DOM 操作都需要改成驼峰命名的方式。之所以 JS 要重新定义这套驼峰逻辑本质上也是没有办法,因为
-在 js 中会被理解成减法运算符,所以只能重写一趟驼峰逻辑。属性值的多样性
html<div style="color: #000"></div> <script> let div = document.querySelector('div') console.log(div.style.color) </script><div style="color: #000"></div> <script> let div = document.querySelector('div') console.log(div.style.color) </script>这里获取到的颜色在不同的浏览器结果可能是不一样的,结果可能会是
#000也有可能会是rgb(0,0,0),所以当需要判断颜色的时候需要严谨的写 if 语句,如:jsif (div.style.color === 'rgb(0,0,0)' || div.style.color === '#000') { alert('颜色为黑色') }if (div.style.color === 'rgb(0,0,0)' || div.style.color === '#000') { alert('颜色为黑色') }
好用的计算样式
写代码也蛮久的了,我是第一次知道 DOM 的这个方法,理解了之后可以说这个方法非常之好用,而且是现代浏览器的标准方法!它就是getComputedStyle看名字像是计算样式。
html
<div style="color: red; font-size: 30px">hello world</div>
<script>
function fetchComputedStyle(element, property) {
const computedStyle = getComputedStyle(element)
if (computedStyle) {
property = property.replace(/([A-Z])/g, '-$1').toLowerCase()
return computedStyle.getPropertyValue(property)
}
}
document.addEventListener('DOMContentLoaded', () => {
const div = document.querySelector('div')
console.log(fetchComputedStyle(div, 'color'))
console.log(fetchComputedStyle(div, 'font-size'))
})
</script><div style="color: red; font-size: 30px">hello world</div>
<script>
function fetchComputedStyle(element, property) {
const computedStyle = getComputedStyle(element)
if (computedStyle) {
property = property.replace(/([A-Z])/g, '-$1').toLowerCase()
return computedStyle.getPropertyValue(property)
}
}
document.addEventListener('DOMContentLoaded', () => {
const div = document.querySelector('div')
console.log(fetchComputedStyle(div, 'color'))
console.log(fetchComputedStyle(div, 'font-size'))
})
</script>使用getComputedStyle可以获取一个 DOM 的计算样式对象,之后使用这个对象的getPropertyValue()方法传递一个属性,即可获取属性值,确实是很好用,尤其是可以和例子那样加个正则,使其支持 CSS 的连字符样式属性!!!
避免布局抖动
布局抖动是很容易发生的事情,原因是当我们强制浏览器执行大量的(可能不需要的)重新计算,这个就是造成布局抖动的元凶。这个问题的元凶就在于,每当我们修改 DOM 的时候,浏览器必须在读取任何布局信息之前先重新计算布局,这就会对性能造成大量的损耗
html
<div style="color: red; font-size: 30px" id="div1">hello</div>
<div style="color: red; font-size: 30px" id="div2">world</div>
<script>
let div1 = document.getElementById('div1')
let div2 = document.getElementById('div2')
// 读写
const div1Width = div1.clientWidth
div1.style.width = div1Width / 2 + 'px'
// 读写
const div2Width = div2.clientWidth
div2.style.width = div2Width / 2 + 'px'
</script><div style="color: red; font-size: 30px" id="div1">hello</div>
<div style="color: red; font-size: 30px" id="div2">world</div>
<script>
let div1 = document.getElementById('div1')
let div2 = document.getElementById('div2')
// 读写
const div1Width = div1.clientWidth
div1.style.width = div1Width / 2 + 'px'
// 读写
const div2Width = div2.clientWidth
div2.style.width = div2Width / 2 + 'px'
</script>一连串的读写对性能的损耗是很大的,我们可以优化代码为:
html
<div style="color: red; font-size: 30px" id="div1">hello</div>
<div style="color: red; font-size: 30px" id="div2">world</div>
<script>
let div1 = document.getElementById('div1')
let div2 = document.getElementById('div2')
// 读
const div1Width = div1.clientWidth
const div2Width = div2.clientWidth
// 写
div1.style.width = div1Width / 2 + 'px'
div2.style.width = div2Width / 2 + 'px'
</script><div style="color: red; font-size: 30px" id="div1">hello</div>
<div style="color: red; font-size: 30px" id="div2">world</div>
<script>
let div1 = document.getElementById('div1')
let div2 = document.getElementById('div2')
// 读
const div1Width = div1.clientWidth
const div2Width = div2.clientWidth
// 写
div1.style.width = div1Width / 2 + 'px'
div2.style.width = div2Width / 2 + 'px'
</script>以上的操作是我们批量的处理读和写,性能上会好很多。
会引起布局抖动的 API 和属性有蛮多的,其中对于 DOM 来说,一些涉及宽高、大小之类的属性如果操作不当就会发生问题。
事件
JS 是单线程+事件驱动的,所以事件是一个非常重要的知识点,事件写好可以极大的优化代码结构,让代码更加的优雅,性能能高!
深入理解事件循环
这里记录了比较多理论的知识,代码相对不好演示,建议小伙伴们自己去看个书。
事件循环前面很简答的记录过一次,在过去,我以为我明白的差不多了,但是当读完书之后才发现自己只是处于一知半解的水平,而且对于自己想的答案并不自信,很多东西之前知道又忘记了,所以这里系统的复习一下:
事件循环比较重要的是我们需要知道两个重要的任务队列: 宏任务,微任务。
宏任务的例子有很多,几乎所有的页面事件、网络事件、定时器事件等等。
微任务的例子过去我只知道一个 Promise,其实还有 DOM 发生变化等等(其实这个我也还是不清晰)。
模型图
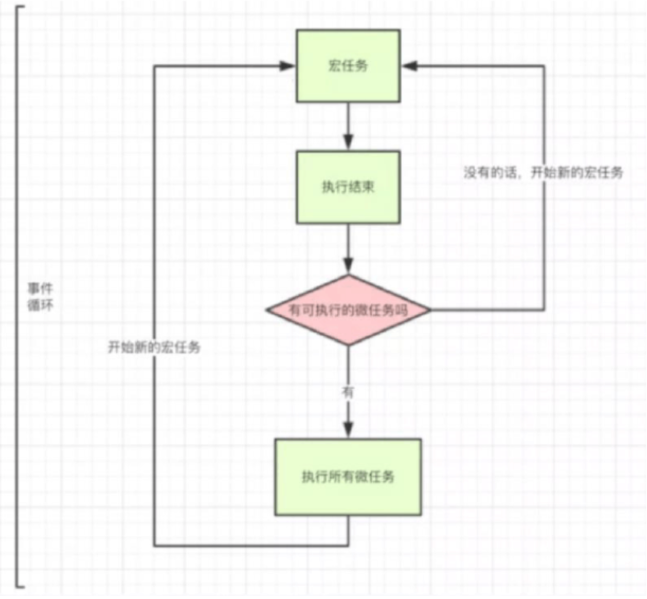
事件循环的基本原则:
- 一次只会执行一个任务
- 一个任务开始后直到运行完成,不会被其他任务中断
- 再一次迭代中,事件循环将首先检查宏任务队列
- 如果有宏任务在等待状态,则会立即执行宏任务。
- 如果没有宏任务,则跳过这个阶段
- 宏任务阶段结束之后会立即转向微任务队列,开始轮询执行微任务,直到微任务全部执行完毕(微任务队列为空),之后会再次转向执行宏任务。
注意点:
- 两类任务都是独立于事件循环的,这意味着添加任务的行为是发生在事件循环之外的(如果不这样也很好理解,在执行 JS 的时候有的任务会被忽略)
- 浏览器通常会尝试每秒渲染 60 次页面(60FPS),这意味着浏览器会尝试在 16ms 内渲染一帧
- 要注意事件处理函数发生的频率以及执行耗时,如鼠标移动事件,如果操作不当会导致页面卡顿,造成用户体验拉跨。所以要注意防抖和节流的使用。
计时器
计时器几乎现在开发离不开了,用它可以很好的做一些调试,页面动画、等其他高阶操作,但是它同样也有着很多的使用细节:
计时器的时间表示的是 至少 指定的时长之后执行回调函数里面的操作
jslet count = 0 for (let i = 0; i < 1000000000; i++) { count++ } setTimeout(() => { console.log('执行结束了') }, 100)let count = 0 for (let i = 0; i < 1000000000; i++) { count++ } setTimeout(() => { console.log('执行结束了') }, 100)以上定时器的时间肯定不是 100 毫秒就执行,因为 setTimeout 的处理函数会被放入到宏任务队列中,主线程的代码执行需要花费时间。所以要清晰 至少 的这个概念。
通过 DOM 代理事件
通过 DOM 代理事件这种操作非常的好用!可以极大的减轻我们的代码量,让代码更加的优化,要使用我们需要将两个恶心的词记清楚:捕获、冒泡。
这个知识点我应该是看了不下五遍,现在终于是能分清楚什么是捕获什么是冒泡了,结合生活实际,冒泡可以想象成烧开水过程,水开了之后气泡从中间向外扩散,捕获可以理解成我们要在某个事件发生之前先捕获到这个事情。用这个方式去记应该就能比较好的分清楚哪个对应哪个了。
addEventLinstener的细节
之前在第一部分内容对比过 addEventLinstener 和 onclick 之类属性绑定的所具有的优势,其实还有其他的优势,使用 addEventLinstener 我们可以指定事件传播方式(冒泡还是捕获)
addEventLinstener 其实是可以接收参数的,过去我们常常只写两个参数就行了是吗,因为第三个参数是有默认值的,如div.addEventListener('click',()=>{},true)第三个参数就是用来表示是事件是冒泡还是捕获
- true:启动捕获模式
- false:启动冒泡模式
W3C 更倾向于默认冒泡,所以默认是冒泡事件,即默认 false。
冒泡
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
#out {
width: 200px;
height: 200px;
background-color: skyblue;
}
#inner {
width: 100px;
height: 100px;
background-color: slateblue;
}
</style>
</head>
<body>
<div id="out">
<div id="inner"></div>
</div>
</body>
<script>
document.body.addEventListener('click', () => {
console.log('body')
})
document.getElementById('out').addEventListener('click', () => {
console.log('out')
})
document.getElementById('inner').addEventListener('click', () => {
console.log('inner')
})
</script>
</html><!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
#out {
width: 200px;
height: 200px;
background-color: skyblue;
}
#inner {
width: 100px;
height: 100px;
background-color: slateblue;
}
</style>
</head>
<body>
<div id="out">
<div id="inner"></div>
</div>
</body>
<script>
document.body.addEventListener('click', () => {
console.log('body')
})
document.getElementById('out').addEventListener('click', () => {
console.log('out')
})
document.getElementById('inner').addEventListener('click', () => {
console.log('inner')
})
</script>
</html>当我们点击 innerdiv 的时候,会输出 inner、out、body,由内向外,就是冒泡事件,没啥毛病。
捕获
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
#out {
width: 200px;
height: 200px;
background-color: skyblue;
}
#inner {
width: 100px;
height: 100px;
background-color: slateblue;
}
</style>
</head>
<body>
<div id="out">
<div id="inner"></div>
</div>
</body>
<script>
document.body.addEventListener(
'click',
() => {
console.log('body')
},
true
)
document.getElementById('out').addEventListener(
'click',
() => {
console.log('out')
},
true
)
document.getElementById('inner').addEventListener(
'click',
() => {
console.log('inner')
},
true
)
</script>
</html><!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
#out {
width: 200px;
height: 200px;
background-color: skyblue;
}
#inner {
width: 100px;
height: 100px;
background-color: slateblue;
}
</style>
</head>
<body>
<div id="out">
<div id="inner"></div>
</div>
</body>
<script>
document.body.addEventListener(
'click',
() => {
console.log('body')
},
true
)
document.getElementById('out').addEventListener(
'click',
() => {
console.log('out')
},
true
)
document.getElementById('inner').addEventListener(
'click',
() => {
console.log('inner')
},
true
)
</script>
</html>这回还是一样的操作,但是输出的内容是相反的,是 body、out、inner,是捕获的过程。
混合使用
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
#out {
width: 200px;
height: 200px;
background-color: skyblue;
}
#inner {
width: 100px;
height: 100px;
background-color: slateblue;
}
</style>
</head>
<body>
<div id="out">
<div id="inner"></div>
</div>
</body>
<script>
document.body.addEventListener(
'click',
() => {
console.log('body')
},
true
)
document.getElementById('out').addEventListener('click', () => {
console.log('out')
})
document.getElementById('inner').addEventListener(
'click',
() => {
console.log('inner')
},
true
)
</script>
</html><!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
#out {
width: 200px;
height: 200px;
background-color: skyblue;
}
#inner {
width: 100px;
height: 100px;
background-color: slateblue;
}
</style>
</head>
<body>
<div id="out">
<div id="inner"></div>
</div>
</body>
<script>
document.body.addEventListener(
'click',
() => {
console.log('body')
},
true
)
document.getElementById('out').addEventListener('click', () => {
console.log('out')
})
document.getElementById('inner').addEventListener(
'click',
() => {
console.log('inner')
},
true
)
</script>
</html>还是一样点击 innerdiv,因为 out 已经被我们改成了冒泡模式,所以最终的结果是,body、inner、out
使用代理模式优化代码
还是上面的例子,当我们如果一个类型的每个 div 都要添加点击事件然后做处理,其实代码是可以稍微优化一下的,借助代理(委托)的思路实现:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
#out {
width: 200px;
height: 200px;
background-color: skyblue;
}
#inner {
width: 100px;
height: 100px;
background-color: slateblue;
}
</style>
</head>
<body>
<div id="out">
<div id="inner"></div>
</div>
</body>
<script>
document.body.addEventListener('click', e => {
switch (e.target.id) {
case 'out':
console.log('点到outer上了')
break
case 'inner':
console.log('点到inner上了')
break
default:
console.log('啥也不是!!!')
}
})
</script>
</html><!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
#out {
width: 200px;
height: 200px;
background-color: skyblue;
}
#inner {
width: 100px;
height: 100px;
background-color: slateblue;
}
</style>
</head>
<body>
<div id="out">
<div id="inner"></div>
</div>
</body>
<script>
document.body.addEventListener('click', e => {
switch (e.target.id) {
case 'out':
console.log('点到outer上了')
break
case 'inner':
console.log('点到inner上了')
break
default:
console.log('啥也不是!!!')
}
})
</script>
</html>使用委托,我们非常清爽的写出了代码,结构非常的清晰,比注册三个事件循环还是好很多的。
总结
事件循环的概念还是非常重要的,加深了理解,另外我清晰了冒泡和捕获的概念,知道了原来默认支持的是冒泡事件。以及如果使用委托相对优雅的写一些特殊的代码。
读后感
这本书对我来说比较特别,因为是 2022 年的第一本书,这本书也是非常纵向的一本书,之前我也阅读过 红宝书、犀牛书,之类在前端界几乎封神的书,读完确实感觉收获很大,但是没有这本书这么大,因为那两本书都是权威类型的,也是横向的知识点讲解,尤其是红宝书涉及到了前端的方方面面,可能因为比较厚我就很难非常认真的每页都看,或多或少会有跳过的部分,以致于读完之后,会的更加深入了,不会的也会了一些,但是难的还是不会(因为被我跳过了)。
但是这本 忍者书,真的很不一样,虽然它是比较早的书,出的时候 ES6 都还没有普及,但是它对这一块的研究真的深入,如、函数、任务队列、事件之类的知识点都是纵向的,而且书中的大部分讲解的内容都能有非常不错的实例,看完就能理解作者想要表达的意思了。一个章节结束之后都有一些课后题,在学习完成之后可以简单的刷一下,非常有利于加深理解!它讲究我们写代码要像忍者一样!所向披靡,以更加优雅和性能最优的方式进行解题。
当然,对我来说意义最大的不是我知识层面的积累,而是我将这本书我过去所不是很清晰的知识点都采用了费曼学习法的方式录制成了视频分享出去,这本书重要的知识点肯定不止我记录的这些,只是这些事相对于我来说比较模糊的知识点,所以还是真正的买一本来看能够获得更大的收获!
最后,谢谢大家的观看!祝大家都能成为一名前端开发的 忍者!