 前端加油站🧠
前端加油站🧠Appearance
git
需求开发流程
当接到一个需求,如:优惠券管理这个后端。可以按照此流程进行下去。
先本地创建一个分支,如:feature/bugcoupouns,并在这个项目上进行基本的需求开发
- 开发过程中如果完成一个功能点就 commit 一次,不要全部完成了之后再一次 commit。
- 多次 commit 记录可以方便回退到以前某个功能点前的代码
- 直到开发完成最后一个 commit 提交
切换到 test 分支,拉取最新的 test 分支的代码。
使用
cherry-pick命令将历史的 commit 记录提交到 同步到 test 上# 只有一个commit git cherry-pick e60d8d20268ad60f3268aa58d8f2a75767d6ccb7 # 多个commit记录 git cherry-pick commit1^..commit2 // [commit1,commit2] git cherry-pick commit1..commit2 // (commit1,commit2]# 只有一个commit git cherry-pick e60d8d20268ad60f3268aa58d8f2a75767d6ccb7 # 多个commit记录 git cherry-pick commit1^..commit2 // [commit1,commit2] git cherry-pick commit1..commit2 // (commit1,commit2]使用
git push将本地代码推送到远端切换回开发分支
将开发分支同步推送到远端
git push -u origin feature/coupons远端也会有一个 feature/bugcoupons 分支,也方便其他人看对代码改动了什么东西.
关于版本回退
版本回退是 git 最棒的功能之一,git 给了我们一个可以犯错的机会,当我们不小心改错代码无法通过撤销操作回去的时候,这时候使用 git 的版本回退的特性,就可以非常好的让我们回到”犯错前“(前提是我们做好相对应的版本提交),以下是几个最重要的命令。
查看提交记录的日志
git loggit log会返回一系列非常长的哈希值,哈希值是版本回退的关键! 也可以配合
git cherry-pick使用
查看历史的 git 操作
git refloggit reflog返回一些对版本的操作,不会包含
git add、git status的记录,所以非常的清晰!
回退历史版本
# git git reset --hard + 哈希值 git reset --hard 225a4b4 # 回退到 225a4b4 这个版本# git git reset --hard + 哈希值 git reset --hard 225a4b4 # 回退到 225a4b4 这个版本命令非常简单,只需要传递一次版本的哈希值即可快速在版本之间切换
总结下来比较关键的就是像同事说的,既然用了 git 就要充分的发挥 git 的作用,在做完一个小功能点的时候就打一次 commit,这是一个好习惯!
git pull --rabase 优化提交记录
事情的起因是我 git 操作不当,被组长说了一下,研究了一下午 终于搞明白了!
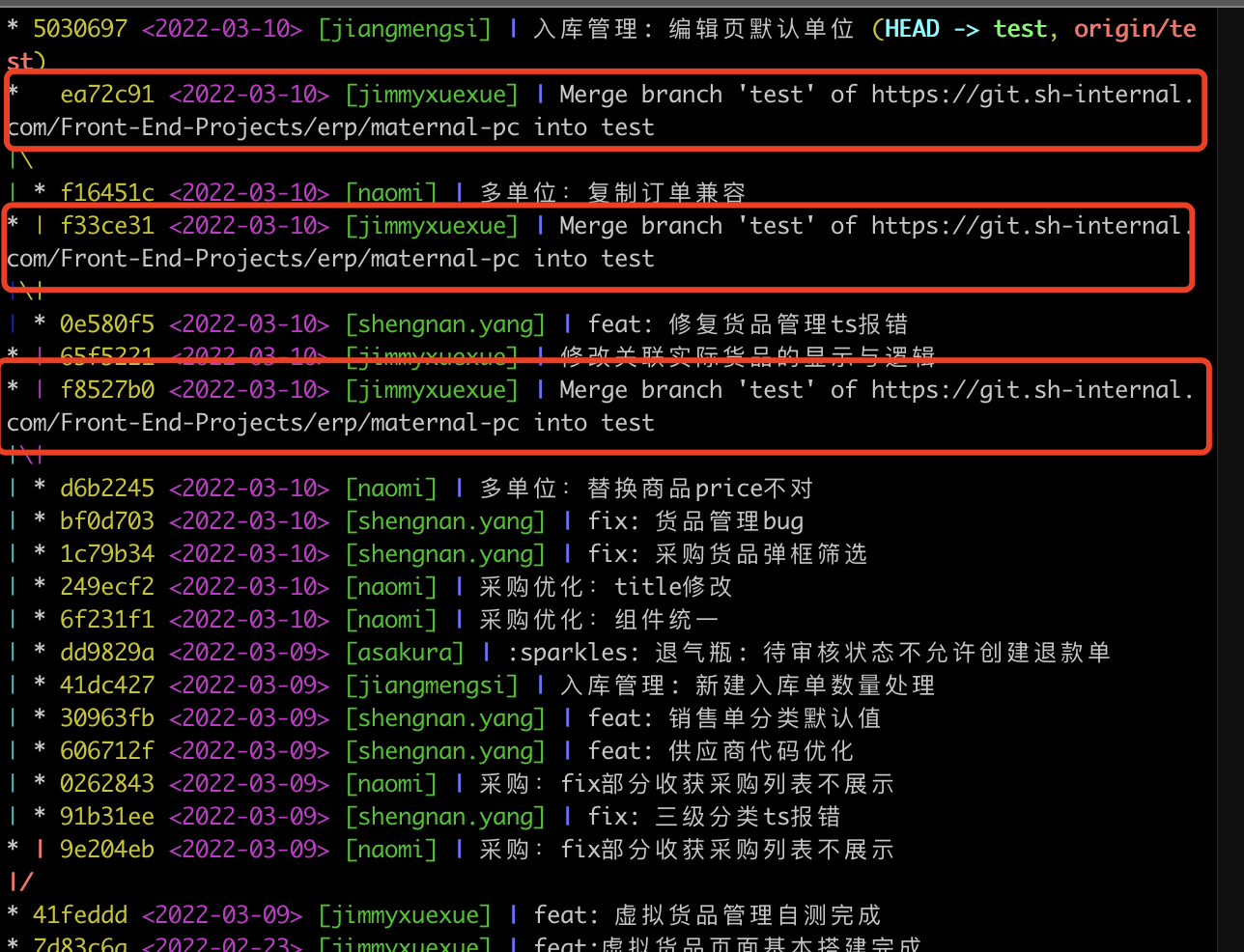
刚开始我其实是很懵的,从始至终我其实都没有打过一个Merge命令,但是从结果日志来看那几个Merge的操作确实是我做的,这就令我非常的不解了,在向公司其他同事请教的过程中得知,导火索其实是git pull 的锅!我的业务场景如下:
我在本地分支完成了我功能的开发,现在需要合并到test分支上,于是我的目标是在test分支上执行git cherry-pick操作将我的代码检出到 test 上,因为我要避免有人更新过 test 分支,所以我在此之前先执行了一下git pull,出现了一个Merge的 vi 窗口(过去我一直没注意,直接就 wq 出去了),其实这个就是导火索!vi 窗口如下:
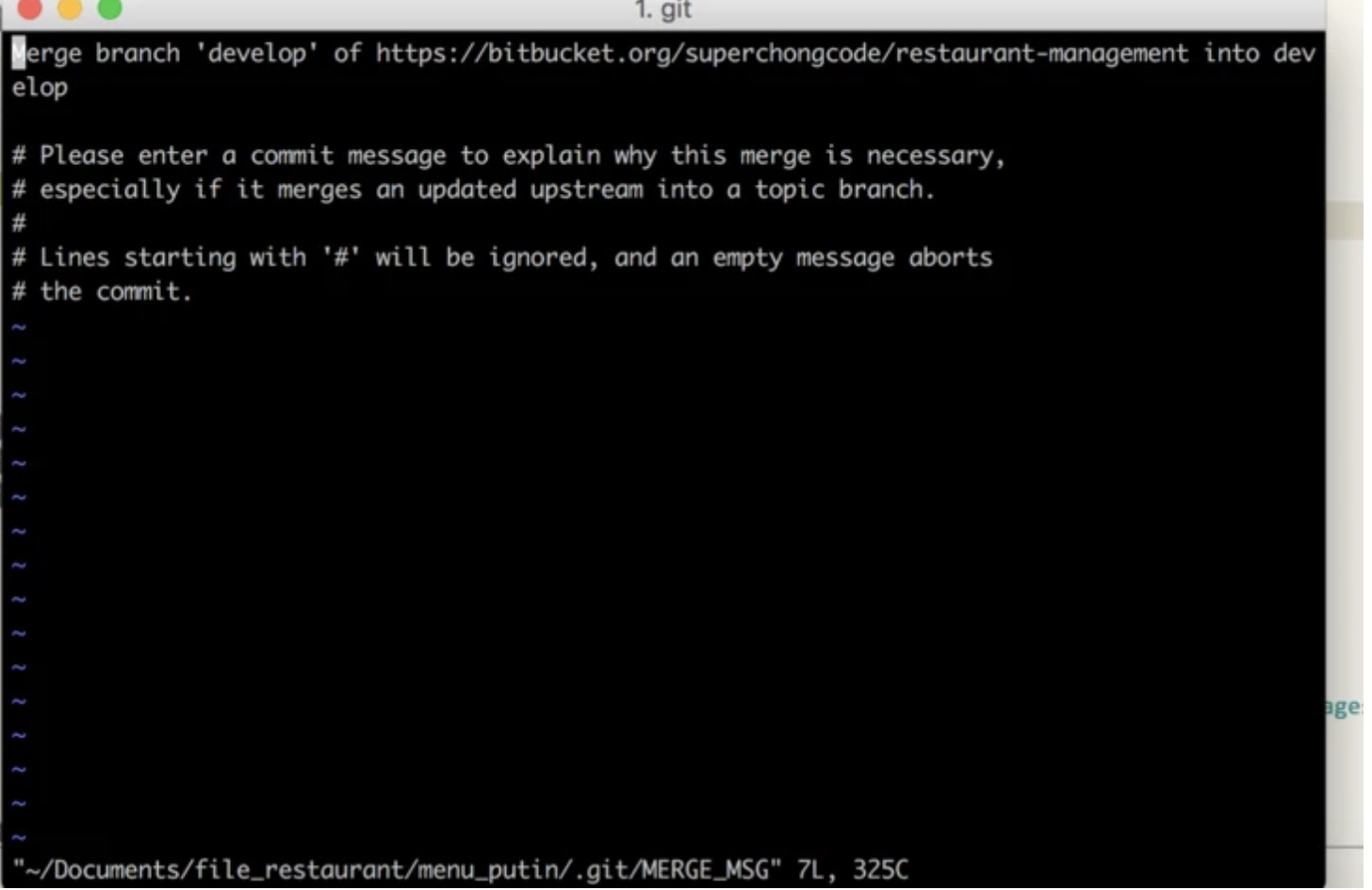
原因
git pull 其实是一个组合操作,其会执行 git fetch + git merge (过去其实完全不知道),因为有git merge的存在,所以最后的提交记录看起来就会很乱。
解决方案
使用git pull --rebase来进行合并本地和远程分支。既可以完美解决这个问题!
git pull --rebase也是一个组合操作,其会执行git fetch + git rebase,我们知道git rebase就是解决凌乱记录的一个大杀器,所以可以完美的解决!
示例代码
git pull --rebase origin test # 拉取test的代码
# 如果有冲突解决冲突,此时的 current 代表的是远程 incomming 代表的是本地的代码
# git rebase --continue 保存冲突解决的状态(注意这时候不能使用 git commit 了)git pull --rebase origin test # 拉取test的代码
# 如果有冲突解决冲突,此时的 current 代表的是远程 incomming 代表的是本地的代码
# git rebase --continue 保存冲突解决的状态(注意这时候不能使用 git commit 了)这样操作之后我们的提交记录就是非常干净的一条链路了!
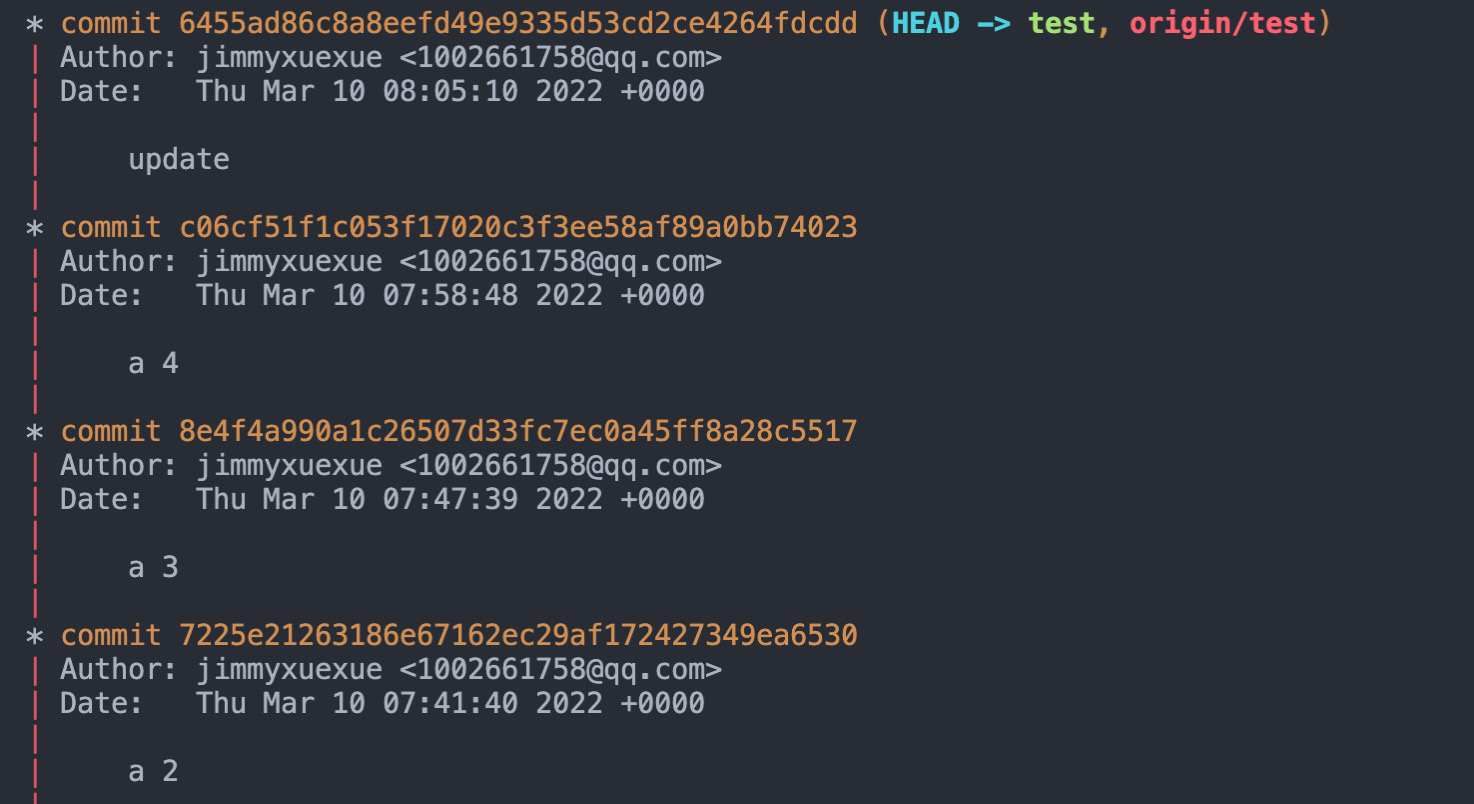
补充
git log --graph更加清晰的结构查看 log 记录
换一个思路使用 git 上传代码
test 分支和 master 分支相比,test 分支中是包含一些新功能的代码,只有测试通过之后才会被放入 master 分支中。
过去由于我操作不当——在开发分支中拉取 master 分支,导致我的开发分支不干净了,中间有很多的其他的提交记录(按道理是不应该有的),这就导致使用 cherry-pick 操作用不了了。
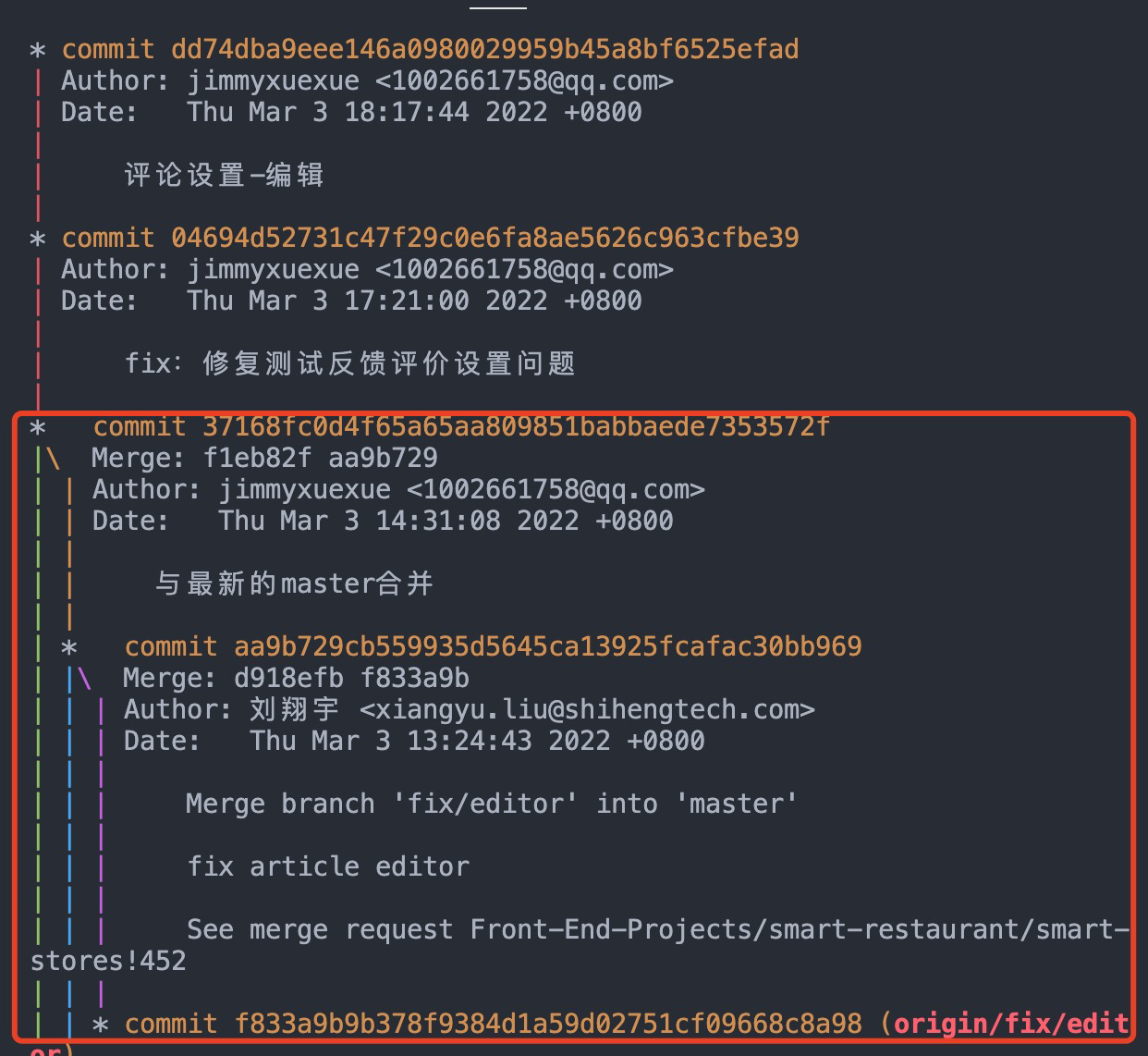 于是我重新的创建了一个干净的分支,在干净的分支上将我这个不干净的分支最后一版本的代码给放过去,再合并到 test 分支上,在实操过程中也是非常的困难,很多的冲突,临近下班之际我还是没有合并好,后面求助了一个带我的大哥,他大概只用了 30 秒,就解决了我快两个小时没有解决的问题.....
于是我重新的创建了一个干净的分支,在干净的分支上将我这个不干净的分支最后一版本的代码给放过去,再合并到 test 分支上,在实操过程中也是非常的困难,很多的冲突,临近下班之际我还是没有合并好,后面求助了一个带我的大哥,他大概只用了 30 秒,就解决了我快两个小时没有解决的问题.....
他的思路
删除了我原来的 test 分支
git branch -D testgit branch -D test他基于我的新分支(已经包含最新代码)创建一个本地的 test 分支,并切换至改分支
git checkout -b testgit checkout -b test基于本地 test 分支拉取远程 test 分支的代码
git pull --rebase origin testgit pull --rebase origin test有冲突解决冲突
push 至远程的 test 分支
git push origin testgit push origin test
这个思路和我的思路方向正好是完全相反的,我一直停留在用 cherry-pick 把我的代码合并到 test 上,但是大哥的方式是把 test 往我的合并,再推送到 test。非常的精髓,全程没用一个 cherry-pick 也实现了合并操作!
git 强推代码
本周我在合并分支的时候,遇到一个从未见过的问题,简单的概括下来就是:
我的开发分支发起 PR 想合并至 master 发现有冲突,无法合并。于是我在本地开发分支(和远程开发分支保持一致的分支)拉取 master 代码,并无一点儿冲突,这就奇怪了!奇怪的点在于:
- 发起 pr 合并提示有冲突
- 直接拉取 master 代码并无冲突
这时候我求助了公司前辈,得知了一种强推代码的方法!
git push origin test -f 简单的说就是加了 -f
流程为:
本地分支拉取 master 代码
推送至远程开发分支
这时候提示有冲突,push 不上去,这时候使用
git push -f强推,这时候 pr 已经无冲突,完美解决!
强推知识点
强推之后,会将远程的代码版本强制与当前本地的版本保持一致,远程的代码就是一个无冲突的版本,有的时候还是非常有用的,但是这个操作也是一个相对危险的操作!
不过就算不小心强推错了也没关系,毕竟 git 有给我们犯错的机会,能够版本回退!
合并 commit
过去使用 git 开发中一直有个痛点困扰着我,那就是会出现一些无用的 commit ,我们都知道一个 commit 就代表一个版本,所以理论上不应该有一些无用的版本,所以学习了一些这一方面的操作,来弥补一下自己 git 在这方面存在的不足;
过去我所遇到的痛点:
当我完成了功能 A 的需求开发,很开心,于是我迫不及待的使用 git 更新了一个版本 commit:
git commit -m "feat: A开发完成"git commit -m "feat: A开发完成"突然,我发现有一些测试代码居然没有删干净,还留着一些测试代码:

要上线的代码肯定不能有这些东西,所以我删去了那些 comsole.log alert 等等无用的代码,删完之后,多了一个版本,不得不再写个 commit:
git commit -m "refactor: 无用代码删除"git commit -m "refactor: 无用代码删除"这就有了两个版本,但其实是自己失误,一个版本就行的, 所以需要将这两个 commit 合并成 一个 commit
git commit --amend -m "message" 合并最近一次的 commit
回到第二步,删除了测试代码之后,我只需要执行此操作,就可以非常完美的解决这个痛点问题!
git commit --amend -m "删除多余的log"git commit --amend -m "删除多余的log"之后再次查看版本,会发现之后的版本已经不见了,成功的将最新的 commit 合并至了前一个 commit!

其他
其实也还是有其他的方法,当初我请教公司一个同事时,他在我电脑上一顿操作也合并了两个 commit,但是感觉操作的步骤相对来说比这个繁琐了好几个档次,对我来说能合并最近一次已经非常够用了,所以同事的那个方法可以暂时先放弃!反正,“能跑就行!”

git 删除本地分支以及远程分支
随着接的需求增加,我们的分支已经不干净了,为了有一个 干净又卫生 的分支,我们需要删除掉一些确定已经无用的分支。
git branch -D feature/A // 删除本地的 feature/A 分支
git push origin --delete feature/A 删除远程的 feature/A 分支 (注意是 push --delete)git branch -D feature/A // 删除本地的 feature/A 分支
git push origin --delete feature/A 删除远程的 feature/A 分支 (注意是 push --delete)删除分支是一个相对危险的操作,一定要确保已经无用了再删除,如果本地和远程都删除了,那就有点儿危险了!
拉取最新的远程分支列表
开发中还是会出现一些并发更新的需求,比如我们开发的 A 需求需求更改到优惠券页面,但是同时在开发的 B 需求也在更改优惠券页面,A 需求基于 B 需求,所以这时候我们就得根据 B 需求的分支进行开发!
因为 B 需求也没有上线,它的代码也没有合并到 master,所以我们无法在 master 上获取 B 需求的代码,因为项目是比较早 clone 到本地的,所以这时候我们使用git branch -a是无法获取到 B 需求的分支的。
所以我们需要更新一下 远程分支列表
git remote update origin -pgit remote update origin -p执行之后,再使用git branch -a就可以获取最新的远程分支列表了,就可以切换到 B 需求的分支了。
采用 rebase 的方式合并 pr
我们知道使用 rebase 是能够优化整个分支的 commit 记录的,不会出现有多条线的情况,会让整个提交记录更加的清晰。
但是我们平时合并 pr 的时候,一版都是merge 操作,其实这个也是可以使用rebase 的方式来合并 pr 的,先对比一下二者的区别:
常规合并 pr
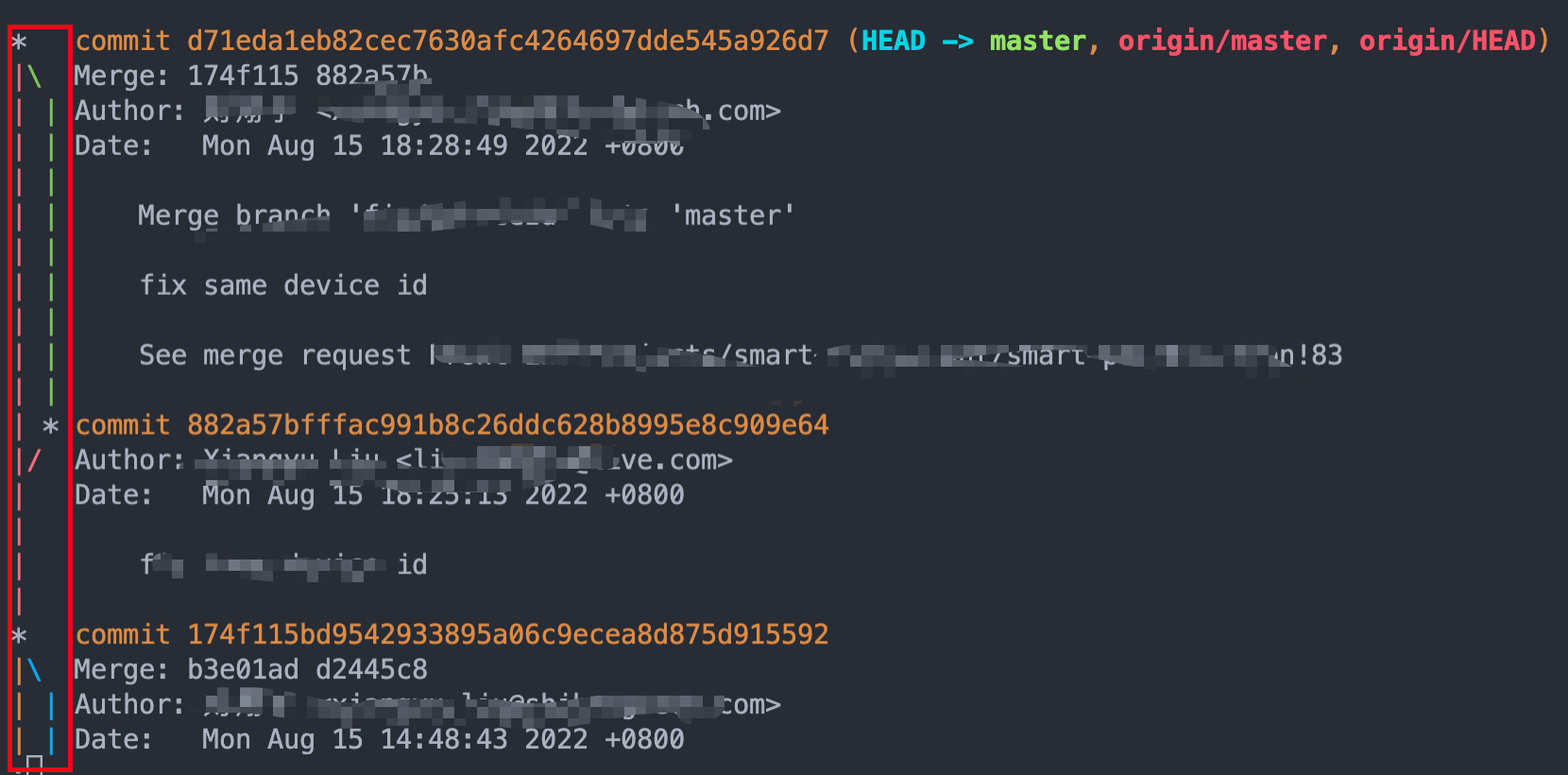
很明显有左侧有多条线,在复杂的情况下可能会有非常多条线,不够清晰
rebase 方式合并 pr

都是一条直线,具体的 commit 记录非常的清晰。
具体是怎么使用 rebase 的方式合并分支呢?其实很简单,在图形化的界面合并按钮处其实是可以选择以哪种方式进行的合并的,这里选择 rebase 的方式即可。
不同的平台(github、gitlab)可能描述不太一样,但是认准有 rebase 的操作即可

更改 git 缓存的账号
本来急的我都想直接重装 git 了..... 还好忍住了。
当克隆一些有权限的项目时我们都需要输入一次账号密码才能克隆,默认情况下 git 会缓存住我们的首次登录的信息,当我们如果更换了一个其他账户之后,克隆的项目的账号密码还是之前第一次输入的账号和密码。
当两个人用一个 git 账号是非常不便的,(不好分锅~)
这也就会导致我们所有的 commit 记录都是另外一个账号的 commit 账号,就算我们把本地的 global 的 git 账户信息改了也是没用的,这时候我们需要重置本机保留的 git config 信息。
git config --system --unset credential.helpergit config --system --unset credential.helper执行之后我们再次clone、push、pull 都会需要输入账号密码,这个也不是我们想要的,需要再次设置成保留 config 信息。
git config --global credential.helper storegit config --global credential.helper store之后我们再次提交就会再次输入一次账号密码,这次的账号密码将会被缓存起来,之后再次操作就不需要再输账号密码了。
强推代码 2
过去当我们所处feature/A分支时,rebase 了 master 的代码之后,可以使用git push -f origin feature/A来强推至远程的feature/A分支。
leader 这回让我重置一下develop分支的代码,其实就是将develop分支的代码同步成为master的代码,所以我的第一想法就是:将master的代码强推至远程的develop分支就好了,也是分分钟的事,于是我做了以下的操作:
我所处的 master 分支
git push -f origin developgit push -f origin develop
结果很明显失败了,原来是命令有错误,虽然我们所处在master分支,做了强推develop的命令,但是这样执行,代码本质的意思是:从本地devlop推到远程develop,所以 git 给的提示是 Evertthing up-to-date,正确的命令应该是:
git push origin master:develop -fgit push origin master:develop -f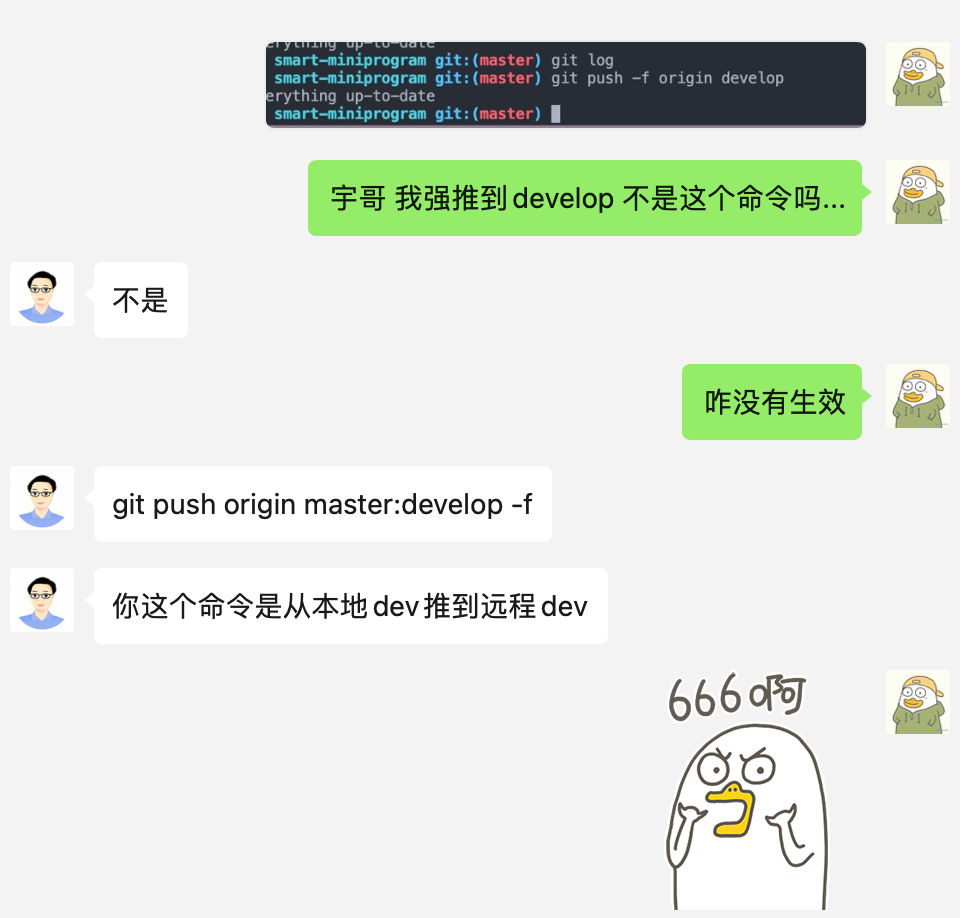
感谢高人指点!又清晰了一个操作。
强制覆盖代码
假设我们处在 test 分支,我需要将 test 分支的代码覆盖成 master 分支的代码,我们可以使用以下这个指令:
git reset --hard master # 处在test分支执行这个指令git reset --hard master # 处在test分支执行这个指令git 绑定多个远程仓库指定推送
假设我们一个本地代码仓库需要同步绑定两个远程仓库地址(虽然这个场景确实比较少,但是还是会有的,如:github 仓库、gitee 仓库、gitlab 仓库),我们想一套代码同步这几个仓库。就需要涉及到以下几个指令:
添加远程仓库地址
git remote add <remote_name> <remote_url>
如:
git remote add githubRemote http://github.com/xxx/zzzz.gitgit remote add <remote_name> <remote_url>
如:
git remote add githubRemote http://github.com/xxx/zzzz.git修改远程仓库地址
git remote edit <remote_name>
如:
git remote edit githubRemotegit remote edit <remote_name>
如:
git remote edit githubRemote执行后会打开一个 vim,更改地址即可
删除远程仓库地址
git remote rm <remote_name>
如:
git remote rm githubRemotegit remote rm <remote_name>
如:
git remote rm githubRemote查看已绑定的远程仓库地址
git remote -vgit remote -v推动代码到指定的远程仓库
前面我们已通过git remote add 添加了不用的远程仓库地址和对应的地址名,所以我们推送的时候加上对应的地址名即可。如:
git push githubRemote mastergit push githubRemote master表示推送到 githubRemote 这个远程名对应的地址仓库的 master 分支。
从 stash 栈中取出指定的暂存内容
查看 stash 栈中已有的内容
git stash listgit stash list推送暂存内容
默认推送内容,我们可以直接使用以下命令来执行。
git stash pushgit stash push但是这样存进 stash 中的内容我们其实没法知道具体是什么内容,如果能够像 commit 一样,存储一些信息,就会好很多,这点 git 肯定也是支持的。使用以下命令即可:
git stash save "<message>""git stash save "<message>""如:git stash save "测试一下"
弹出 最近一次 存入的 stash 内容
这个就和我们编程世界理解的栈是一样的,后进先出的,所以弹出最近一个是使用 pop 命令。
git stash popgit stash pop应用指定的 stash 栈中的内容。
假设 stash 栈中有三条数据,我只想取出第二条数据。
这是一个非常常见的场景,最恶心的是 pop 两次,但是思路上是不对的,这样我们会将无用的内容带入项目,也会丢失最新的 stash 栈中的内容。
正确思路应该是使用apply命令
git stash apply <stashKey>git stash apply <stashKey>如:git stash apply stash@{2}
这个操作试验过在 windows 电脑可能会有一些字符的兼容性,我们可以使用另外一个指令:
git stash apply --index <indexKey>git stash apply --index <indexKey>如:git stash apply --index 2
使用 apply 指令取出 stash 内容,stash 栈本身仍然会存在,并未被删除,所以还需要最后再了解一下如何删除指定的内容。
删除指定的 stash 记录
git stash drop <stashKey>git stash drop <stashKey>如:git stash drop stash@{0}
不过 drop 指令就不支持使用--index 的方式来删除记录了
Revert 之后合并分支
有时我们在发版前,由于一些其他原因,产品可能会说这个需求不上了,我们需要代码回滚,这时候我们可以用 revert 一下代码。 revert 了之后,我们又用开发分支去合 pr,就会出现一个很奇怪的场景:没有文件变动,如下

通过检查一下 master 分支,发现我们开发分支的一些 commit master 上任然是有的。所以这个就是原因。

解决办法
- 蠢办法 新建一个新的分支,把改动内容带到这个分支去合 pr
- 基于最新 master,创建新分支,rebase 一下我们的开发分支,再用这个分支去合代码即可。
- 再次 revert 掉上一个 revert 分支 这是最方便的操作,等于再新增一个 commit 把之前删掉的内容又补回来
修改 git 大小写追踪
这个问题可能比较难碰到,但是一但碰到是很难排查的,非常诡异的问题,可能会出现一个 Git 仓库代码,A 电脑能跑,B 电脑报错,说 xxx 文件找不到。其实这个就是没有开启 git 大小写追踪导致的。我们最好是给电脑开启这个配置:
git config core.ignorecase false # 关闭忽略大小写
git config core.ignorecase true # 开启忽略大小写git config core.ignorecase false # 关闭忽略大小写
git config core.ignorecase true # 开启忽略大小写git tag 相关操作
Git 可以给仓库历史中的某一个提交打上标签,以示重要。其的概念和分支也是也类似的,也有分本地 tag 与远程 tag。
与分支的区别在于,标签(tag)是不可更改的,因为它们被用作固定的版本标识。一旦创建了标签,就不能直接修改它所指向的提交点或为标签添加新的提交。
查看已有 tag
git taggit tag创建 tag
git tag <标签名>git tag <标签名>如:git tag v1.0.0
将 tag 推送至远程
git push <远程名> <tag>git push <远程名> <tag>如:git push origin v1.0.0
切换至指定 tag
git checkout taggit checkout tag如:git checkout v1.0.0
删除本地 tag
git tag -d <tag>git tag -d <tag>如:git tag -d v1.0.0
删除远程 tag
git push --delete <远程名> <tag>git push --delete <远程名> <tag>如:git push --delete origin v1.0.0
总结
以上便是 tag 涉及的一些基础操作,个人认为它和分支的概念是非常像的,它的核心点在于一旦创建了标签,就不能直接修改它所指向的提交点或为标签添加新的提交。
合并多个历史的分支
大家在使用git的过程中一定遇到过有一些意义不大的 commit 的情况吧。这时候我们可能就会需要将多个 commit 的操作。
之前介绍过一个 git commit --amend 将当前commit合并到上一个commit 的操作,但是这个并不适用于一些更加复杂的场景。
举个例子🌰:

我想将这里多个 commit 进行一些合并,这时候我们就会需要使用到一条新的 git 的指令 git rebase -i
将一些意义不大的多个commit 进行合并是挺有意义的,比如我们去rebase远程的代码时,其实这个过程git是按照 commit 来进来合并代码的。极端情况下,我如果有 30 个意义不大(可合并的 commit )没有合并时,并且都有冲突时,最多我可能需要 解 30 次冲突。但是我如果将他们合并成一个commit,那么这样只需要解一次冲突即可。在效率上会快很多很多。
这个场景可能是我前期对于git使用不规范而导致的,希望有看文章或者视频的同学不用跟我争论,多学习一条指令也是好的。
参考的文档:传送门 这里参考了csdn上一个哥们的文章。
基本指令
git rebase -i HEAD~ngit rebase -i HEAD~n这里的n,表示的是 你要取从 头指针开始的几条commit。这个HEAD是可以切换的,你多个 commit 当中的其中一个 commit 的 hash 值即可。
这里我假如我把 HEAD 改成 4.js 的 hash,然后n取2,执行指令:
git rebase -i cd4e5a0bed48dd9c3196170a71bc3277cd2934be~2git rebase -i cd4e5a0bed48dd9c3196170a71bc3277cd2934be~2会出现如下的 vim 终端: 
同理,如果将n改为3,那么这时候就会取到2.js的commit
git rebase -i cd4e5a0bed48dd9c3196170a71bc3277cd2934be~3git rebase -i cd4e5a0bed48dd9c3196170a71bc3277cd2934be~3
了解了这个之后,我们再来研究如何合并commit,简短的一句话,就是commit的关键字,如现在上面圈的关键字是pick,这块的关键字总共有如下几种:
pick
使用这个commit(这场景下可以理解成,啥也不改)
reward
使用这个commit,同时修改commit 信息
知道这个之后,我们基本也就知道了 如果改某个commit的 commit描述信息了
squash
使用这个commit,将commit信息合入上一个commit
这个是我比较推荐的关键字,这样不仅合并了,也能比较清晰的知道,这个大commit是由其他commit一起合并进来的
fixup
使用这个commit,丢弃commit信息
这个也可以实现合并commit,但是他会相对危险一点,因为是属于直接丢弃掉commit信息
现在假设我需要将3.js和4.js这两个commit合并到2.js,这时候我们就在 vim 里面修改 pick关键字就可以了,这里推荐使用 squash 关键字,我们就这么做:
注意,squash 是将commit信息合并入上一个commit 这里需要理解一下上一个的概念,上一个就是2.js

之后vim我们执行 :wq 保存退出,会出一个新的vim 让我们完善一下commit信息,这一步可以直接保存退出,也可以再单独加一些commit信息,这里我就加一点信息

这时候我们再执行git log 看看commit 数据,就会发现,2,3,4被和合并到一起了: 
总结
虽然git用了很久,但是git给我的感觉像是一本读不完的书,算是又了解到了一个新的操作。
当大家有这种需要合并commit场景时,可以使用git rebase -i来进行合并。核心是需要了解 上述介绍的四个 commit 的关键字,了解之后可以帮我们做很多其他的操作。希望这个文章和视频有帮助到大家☀️。